À quoi ressemble une règle pour les recommandations ?
Tout d'abord, nous souhaitons clarifier la manière dont l'agent procède pour définir précisément les règles relatives aux algorithmes d'auto-apprentissage pour les recommandations. Ceux-ci lui permettent d'influencer les recommandations e-commerce sur chaque nouvelle page consultée d'une boutique en ligne.
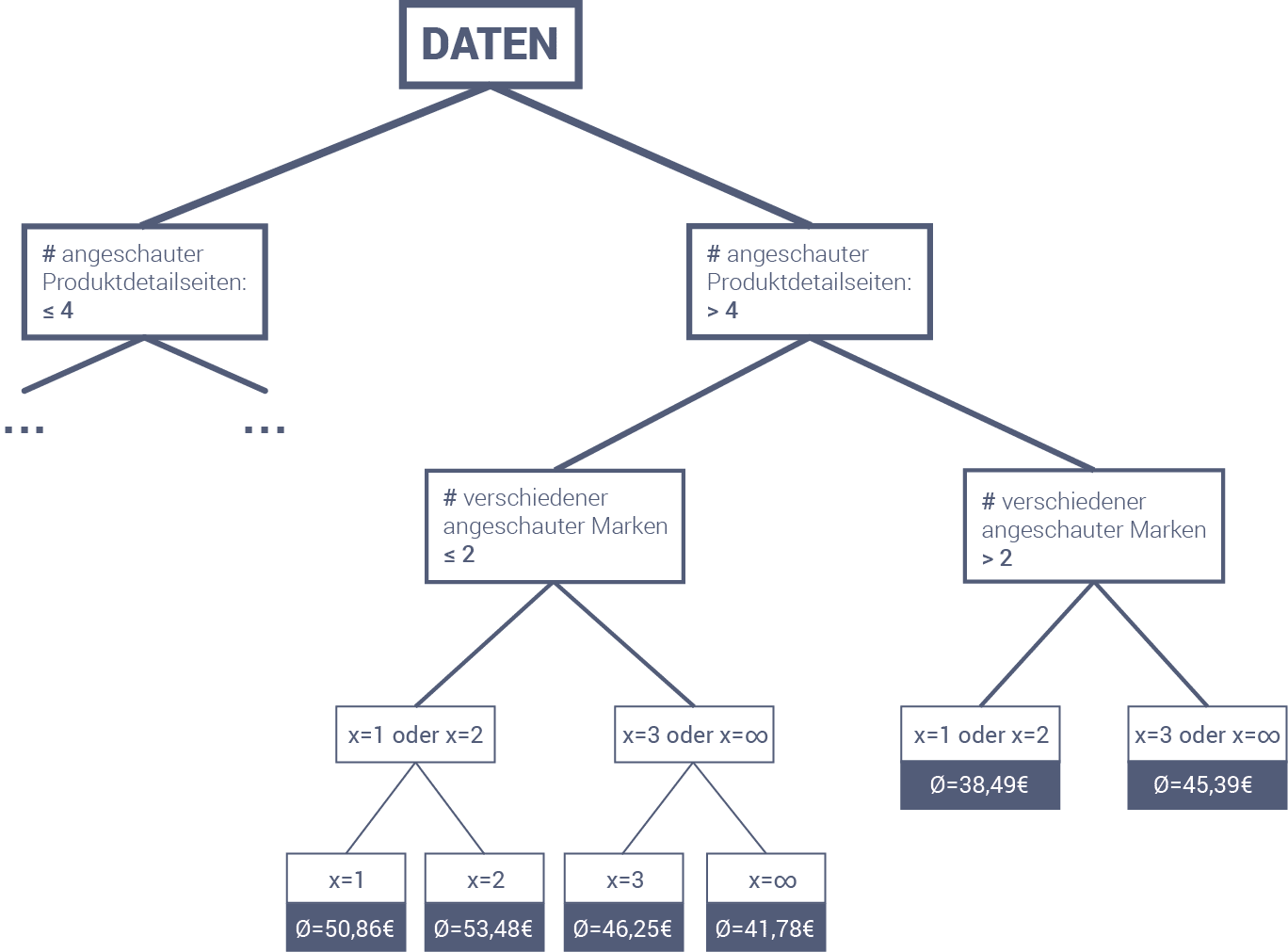
Pour cela, nous examinons à quoi peut ressembler une règle issue d'un système de règles : « N'afficher que les produits des marques x que le client a le plus souvent consultés ». Le x peut prendre les valeurs 1, 2 ou 3 ainsi que ∞. Dans ce cas, ∞ signifie que les recommandations ne sont pas limitées à certaines marques.
Une fois qu'une règle a été établie, l'agent a pour tâche, à l'aide d'algorithmes d'auto-apprentissage, de déterminer quand quelle valeur de x est la plus appropriée. L'agent prend cette décision sur la base des données utilisateur suivies individuellement. Cela signifie qu'il peut prendre une décision différente pour les clients sensibles à la marque et pour les clients qui ne montrent aucune préférence pour une marque particulière.
Restez informé des dernières nouveautés en matière de personnalisation : inscrivez-vous à la newsletter Epoq. Inscrivez-vous dès maintenant !