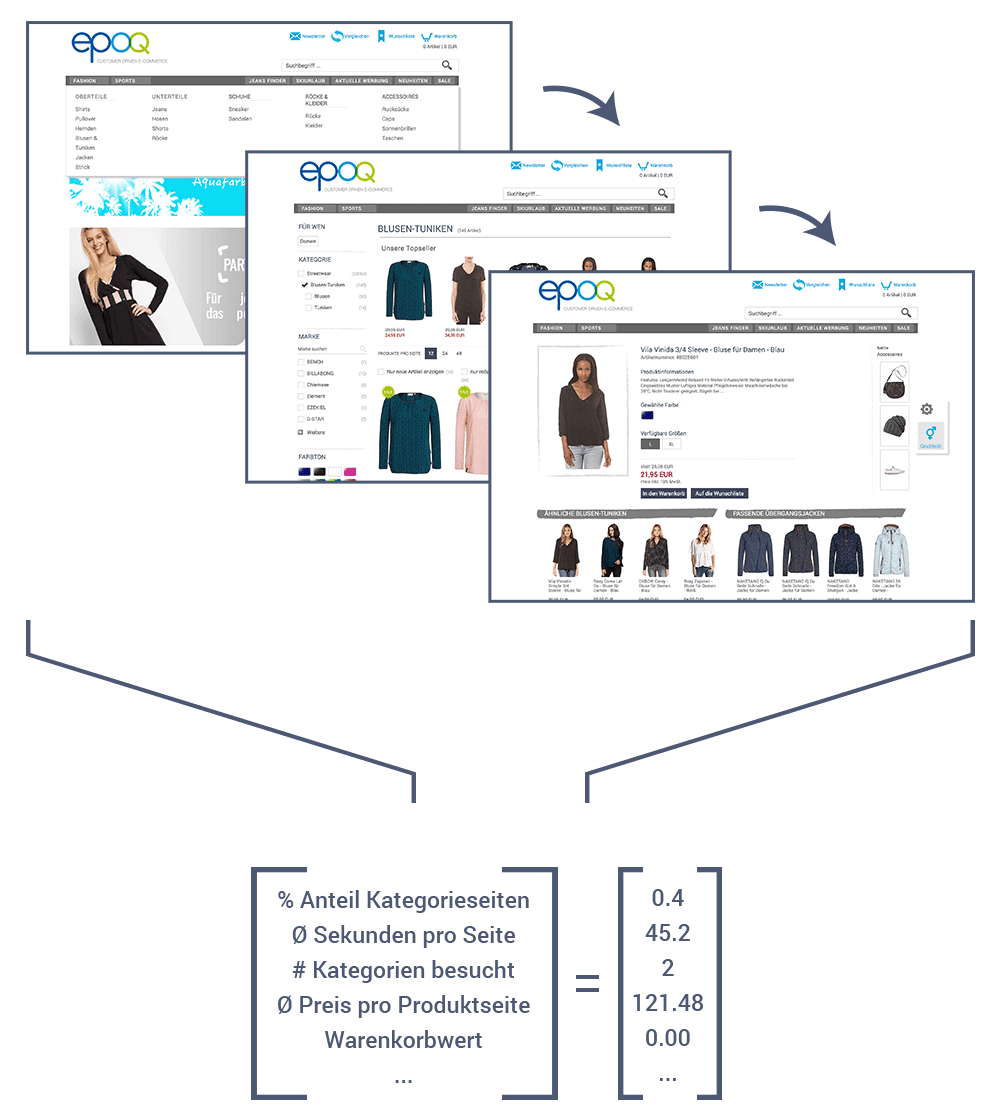
Reconnaître des modèles dans le Big Data
Le nombre de points de données que le serveur peut collecter est énorme. Ainsi, plusieurs milliers de données individuelles peuvent être rapidement rassemblées pour une seule requête de recommandations. Il y a plusieurs raisons pour lesquelles il n'est pas judicieux que l'agent traite toutes les données. Tout d'abord, cela prend plus de temps au serveur. Or, notre objectif est de fournir des recommandations en temps réel.
Si les données sont trop nombreuses, l'agent peut également avoir des difficultés à identifier les modèles importants dans les données. Pour comprendre pourquoi, reprenons l'exemple de la première partie de la série d'articles , dans lequel nous apprenons à notre chien Benno à rapporter une balle.
On pourrait essayer l'entraînement sur une place libre dans une zone piétonne. Cependant, il sera très difficile d'apprendre au chien à courir après la balle lancée. Le chien est soumis à de nombreux stimuli. Il devra éviter les nombreux passants, il sera attiré par l'odeur des stands de currywurst, les cris et les hurlements des enfants et, surtout, les jolies chiennes, qui sont bien plus intéressantes qu'une drôle de balle qui s'envole. Le chien ne parviendra donc pas à se concentrer sur l'essentiel.
Il en va de même pour notre agent d'apprentissage par renforcement. Si on lui fournit trop de données à apprendre, il peut devenir difficile de distinguer les modèles importants des modèles moins importants.
Si vous emmenez votre chien de la zone piétonne au parc, il peut encore y avoir de nombreux stimuli qui rendent l'entraînement difficile. Les chiens de chasse, en particulier, peuvent développer un goût pour la course non seulement après une balle, mais aussi après tout ce qui s'éloigne rapidement d'eux, comme les écureuils, les cyclistes ou les bourdons. Ils courent alors après eux aussi.
De tels effets peuvent également se produire lors de la formation de l'agent. Par exemple, les clients pourraient consulter des produits haut de gamme dans la catégorie des aliments pour animaux et se voir recommander des ballons de football dans la fourchette de prix de 30 à 50 euros. À ce stade, cela pourrait générer un chiffre d'affaires important. Cependant, cela peut aussi être le fruit du hasard et ne pas constituer cette fois-ci un modèle que l'agent doit apprendre. Dans ce cas, l'agent apprendrait à tort à recommander à nos amis des animaux des ballons de football dans la gamme de prix moyenne. Plus l'agent reçoit de données pour son apprentissage, plus le risque que de tels modèles aléatoires apparaissent est élevé.