
E-book – Le vendeur numérique – Renforcement de l'apprentissage dans le commerce électronique
Obtenez des informations complètes sur l'utilisation du renforcement de l'apprentissage pour personnaliser les boutiques en ligne.
L'intelligence artificielle (IA) est désormais incontournable dans de nombreuses entreprises. Elle permet d'automatiser les processus, d'offrir de nouveaux services aux clients et de perfectionner les produits. Dans le commerce électronique, l'IA est par exemple utilisée à des fins de personnalisation, sous forme de chatbots et dans les moteurs de recherche intelligents. L'apprentissage supervisé est une forme d'intelligence artificielle. Découvrez dans notre article ce qui se cache derrière ce modèle, comment il fonctionne et quels sont ses avantages et ses défis.

Voicice quevous trouverez dans cet article de blog :
Qu'est-ce que l'apprentissage supervisé ?
Comment fonctionne l'apprentissage supervisé ?
Quand utilise-t-on l'apprentissage supervisé ?
Avantages du modèle d'IA
Défis liés à l'apprentissage supervisé
Autres formes d'apprentissage automatique
Conclusion : l'apprentissage supervisé offre un grand potentiel aux boutiques en ligne
Questions fréquentes sur l'apprentissage supervisé
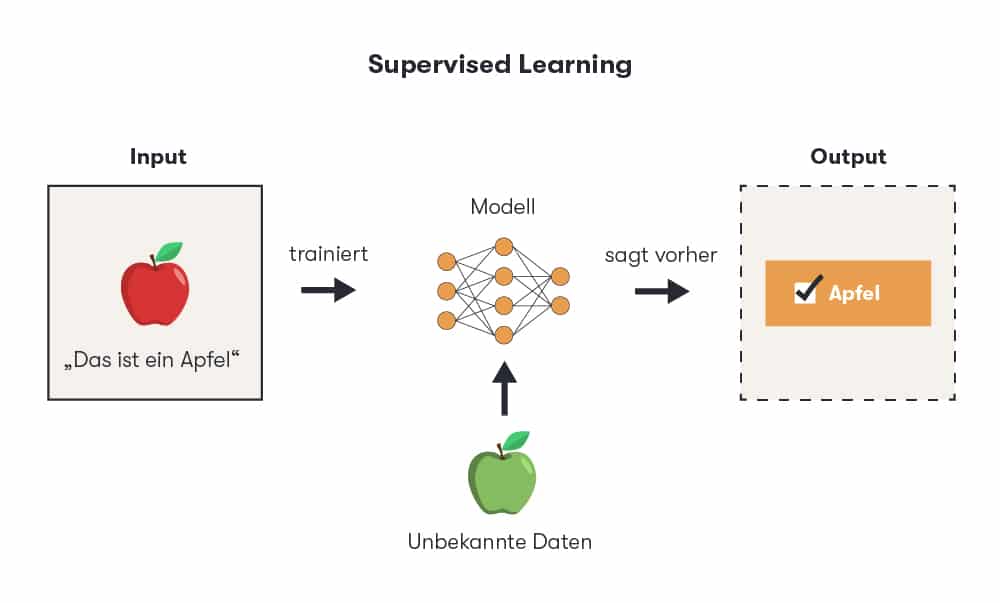
Le «supervised learning» (apprentissage supervisé)désigne une approche visant à développer l'intelligence artificielle (IA). Comme pour toute forme d'apprentissage automatique, l'IA doit être entraînée à l'aide d'algorithmes et de modèles statistiques afin de tirer des conclusions pertinentes à partir d'un ensemble de données donné. Outre le supervised learning, l'apprentissage automatique distingue également le semi-supervised learning (apprentissage semi-supervisé), l'unsupervised learning (apprentissage non supervisé) et le reinforcement learning (apprentissage par renforcement ). Toutes ces formes servent à développer ou à améliorer de nouveaux produits, processus et services.
Dans le cadre de l'apprentissage supervisé, les scientifiques des données entraînent un algorithme informatique et le surveillent pendant son apprentissage. Ils lui fournissent d'abord une multitude de données d'entrée, chacune portant une étiquette pour la sortie requise. Le résultat est donc connu à l'avance. L'algorithme est entraîné jusqu'à ce qu'il puisse reconnaître avec certitude les modèles et les relations sous-jacents entre l'entrée et la sortie.
Restez informé des dernières nouveautés en matière de personnalisation : inscrivez-vous à la newsletter Epoq.Inscrivez-vous dès maintenant!
La machine passe ensuite par une phase de test avec des données d'entrée sans étiquette apparente. Elle décide alors elle-même quelle est la sortie correcte et compare son résultat avec celui spécifié par les développeurs. Les différences ou les prévisions concrètes sont utilisées pour l'optimisation lors de la phase d'apprentissage suivante. La précision ainsi mesurée de l'algorithme montre donc dans quelle mesure celui-ci a déjà appris et ce à quoi on peut s'attendre dans la pratique. L'objectif : l'algorithme doit fournir une sortie aussi précise que possible lorsqu'il est alimenté par des données inconnues sans étiquette après la phase de test.
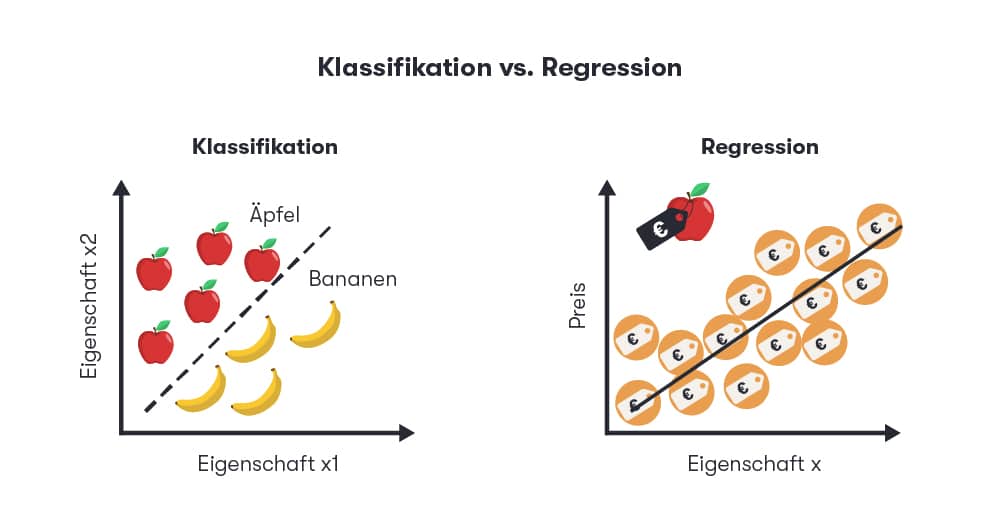
Cette forme d'intelligence artificielle est déjà utilisée pour de nombreuses applications dans le commerce électronique. Elle est particulièrement adaptée aux classifications et aux analyses de régression :
L'apprentissage supervisé aide à résoudre des problèmes concrets, tels que la détection des fraudes à la carte de crédit ou le filtrage des spams, en automatisant différents processus. Cela permet d'économiser du temps et de l'argent à long terme.
Sur la base d'expériences antérieures, la machine peut prédire les développements futurs. Dans le cas du spam, par exemple, elle reconnaît certains mots qui apparaissent dans le texte de l'e-mail, dans l'objet ou dans l'adresse de l'expéditeur. L'entraînement de l'IA aide à obtenir une idée précise des classes d'objets à évaluer. À long terme, cela permet d'automatiser et d'uniformiser l'évaluation et la classification fastidieuses de grands ensembles de données. Une IA bien entraînée surpasse les performances d'un opérateur humain, ce qui permet non seulement de libérer des ressources humaines, mais aussi de réduire le risque d'erreurs.
Pour que la machine puisse reconnaître les corrélations de manière fiable, les données doivent être bien préparées. En effet, des données erronées ou une préparation insuffisante de celles-ci constituent un défi majeur. L'apprentissage non supervisé « compense » cela en laissant un être humain interpréter les résultats, ajuster les paramètres et recalculer. Cependant, comme cela se fait principalement manuellement, cela implique un investissement important en temps et en argent. Les problèmes liés aux données ou à leur traitement insuffisant ne constituent toutefois pas seulement un défi pour l'apprentissage supervisé, mais aussi pour tous les autres processus d'apprentissage. L'apprentissage profond peut compenser en partie ce problème grâce à un temps de calcul et une quantité de données extrêmement importants, mais des données bien préparées sont bien sûr également utiles dans ce processus. C'est ici que s'applique le principe « garbage in, garbage out », car le résultat dépend en grande partie des données saisies.
S'il y a des doublons, des contenus manquants ou des liens manquants dans l'ensemble de données, l'IA ne sait pas quoi en faire. Il en va de même lorsque les données de test diffèrent de l'ensemble de données d'entraînement. En effet, la machine ne doit pas être trop précisément entraînée sur les données d'entraînement. Sinon, on assiste à un effet dit de « surajustement » : ce n'est que lorsqu'une entrée de données correspond exactement aux variables prédéfinies qu'elle peut être classée dans la catégorie correspondante. Le super-apprentissage n'est pas le seul à être confronté à ce défi. Le deep learning n'est pas non plus à l'abri de cet effet.
De plus, il est important de disposer de données variées afin que la machine puisse évaluer autant de scénarios différents que possible. Si elle doit par exemple apprendre à distinguer les humains des animaux sur des images, elle doit voir non seulement des chiens, mais aussi des girafes, des éléphants ou des gorilles. Les scientifiques spécialisés dans les données doivent donc disposer de connaissances suffisantes sur les différentes classes d'objets afin de les distinguer clairement pour l'IA.
L'apprentissage par renforcement est également concerné par les problèmes mentionnés, voire dans une mesure encore plus importante en raison de la nature même de cet apprentissage.
Outre l'apprentissage supervisé, il existe, comme mentionné précédemment, trois autres formes d'apprentissage automatique : l'apprentissage non supervisé, l'apprentissage semi-supervisé et l'apprentissage par renforcement.
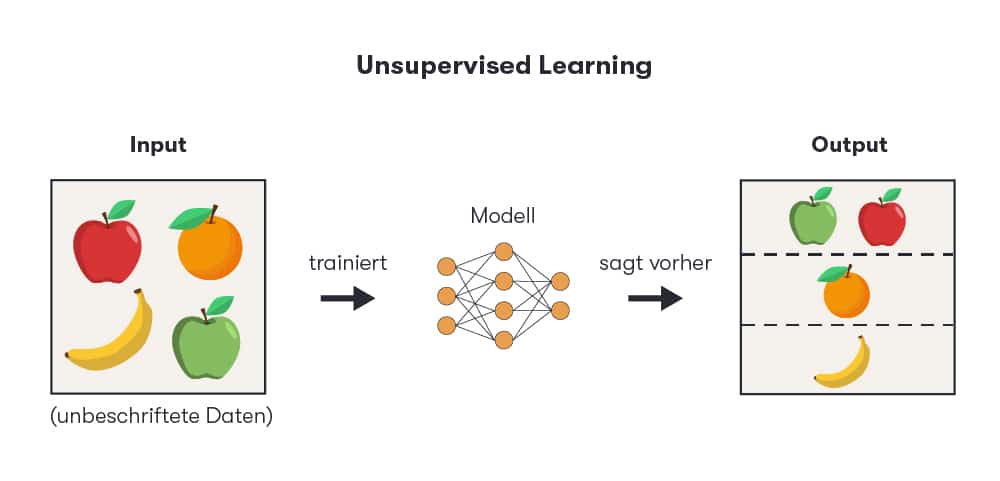
Dans le cadre de l'apprentissage non supervisé , la machine reçoit des données qui n'ont pas été préalablement étiquetées. L'IA doit déterminer elle-même les modèles et les similitudes entre les données. Pour cela, elle a besoin d'un nombre suffisamment important de données – bien plus que dans le cas de l'apprentissage supervisé – afin de pouvoir les regrouper de manière fiable et tirer des conclusions logiques.
La création de segments pour l'analyse des groupes cibles est un exemple d'utilisation de cette forme d'intelligence artificielle. Celle-ci peut à son tour être utilisée pour diffuser des contenus personnalisés pour différents segments.
L'apprentissage semi-supervisé est une forme mixte entre les deux. Pendant l'entraînement, la machine reçoit des ensembles de données avec et sans étiquette. Cette forme d'apprentissage automatique est appropriée dans les cas où il n'y a pas suffisamment de données qualitatives avec étiquette disponibles. Un exemple d'application typique est la reconnaissance faciale. Il suffit de marquer une personne spécifique sur quelques images pour que l'IA trouve de manière autonome d'autres images sur lesquelles cette personne apparaît.
Restez informé des dernières nouveautés en matière de personnalisation : inscrivez-vous à la newsletter Epoq.Inscrivez-vous dès maintenant!
Dans le modèle d'apprentissage par renforcement (reinforcement learning ), les scientifiques des données utilisent des récompenses et des punitions pour enseigner un certain comportement à l'intelligence artificielle. L'algorithme apprend de manière autonome, par essais et erreurs, une stratégie visant à maximiser les récompenses. Initialement utilisé pour l'apprentissage des jeux de société, l'apprentissage par renforcement optimise aujourd'hui de nombreux processus dans le commerce électronique. Si vous souhaitez en savoir plus sur l'apprentissage par renforcement, n'hésitez pas à lire notre série d'articles de blog sur le processus d'apprentissage par renforcement.
Vous pouvez utiliser l'intelligence artificielle de nombreuses façons dans votre boutique en ligne afin de susciter l'enthousiasme de vos clients pour votre marque et de générer un chiffre d'affaires plus élevé. Il est nécessaire de choisir le modèle d'IA adapté à chaque cas d'utilisation. L'apprentissage supervisé offre un grand potentiel pour optimiser les processus et les produits de votre boutique en ligne. Utilisez l'IA pour filtrer vos e-mails dans le service clientèle, proposer à vos clients des contenus personnalisés ou obtenir des prévisions sur les ventes futures.
L'apprentissage supervisé est une forme d'apprentissage automatique. Les scientifiques des données entraînent une machine à reconnaître les relations entre les données et à en tirer des conclusions. Le résultat est connu à l'avance, de sorte que l'IA peut apprendre à s'améliorer en comparant le résultat du calcul et la spécification. Exemple : filtrage des spams dans les e-mails entrants.
Dans le cadre de l'apprentissage supervisé, un algorithme informatique est d'abord entraîné à l'aide d'ensembles de données préparés. Chaque entrée porte une étiquette correspondant au résultat requis. Le modèle d'IA passe ensuite par une phase de test avec d'autres données jusqu'à ce que le résultat corresponde le plus précisément possible aux résultats requis.
Cette forme d'intelligence artificielle est particulièrement adaptée aux classifications et aux analyses de régression, c'est-à-dire à la recherche de relations facilement compréhensibles entre des variables. Elle aide à résoudre des tâches réelles telles que la catégorisation d'articles de blog ou la détection de fraudes à la carte de crédit.
L'entraînement de l'intelligence artificielle nécessite beaucoup de travail manuel et prend beaucoup de temps. Les données doivent être bien préparées, variées et clairement définies dans leur contexte.
Dans le cadre de l'apprentissage supervisé, l'algorithme est alimenté par des données étiquetées afin que l'intelligence artificielle puisse reconnaître les modèles dans les ensembles de données. Dans le cadre de l'apprentissage non supervisé, les données ne sont pas étiquetées. L'IA doit donc établir elle-même des liens entre les différentes variables. L'apprentissage semi-supervisé combine les deux formes : une partie des données est étiquetée, le reste ne l'est pas.
Tu souhaites en savoir plus sur l'apprentissage par renforcement dans le commerce électronique ?
Alors procure-toi notre e-book sur le sujet !
