
Guide pratique | Enrichissement des données – Prendre des décisions ciblées (#EpoqPXD22)
Dans cet espace, les intervenants présentent différentes solutions en matière de gestion des données.
Les boutiques en ligne qui fonctionnent bien génèrent d'énormes quantités de données. Afin d'exploiter ces données et de les transformer en informations utiles, le data mining utilise des algorithmes d'auto-apprentissage. Ceux-ci identifient des modèles qui permettent aux entreprises d'en apprendre beaucoup sur leurs clients. Découvrez ici ce qu'est le data mining, comment il fonctionne et comment vous pouvez l'utiliser à votre avantage.

Voicice quevous trouverez dans cet article de blog :
Définition du data mining et distinction par rapport au big data
Avantages importants du data mining dans le commerce électronique
Exemples d'application du data mining dans le commerce en ligne
Il existe différentes méthodes de data mining
Classification sur la base de caractéristiques
Regroupement par analyse de clusters et segmentation
Découverte de dépendances à l'aide de règles d'association et de séquences
CRISP-DM : un flux de travail standardisé
1. Définition des tâches : compréhension de l'activité
2. Sélection des ensembles de données pertinents : compréhension des données
3. Préparation des données : préparation des données
4. Sélection et application de méthodes d'exploration de données : modélisation
5. Évaluation et interprétation des résultats : évaluation
6. Application des résultats : déploiement
Conclusion : utilisez le data mining pour découvrir ce que révèlent vos données clients.
Le data mining désigne la recherche de modèles dans les données afin de les rendre exploitables. Ces modèles ou corrélations empiriques doivent être identifiés de manière aussi automatisée que possible à l'aide d'algorithmes. Cette méthode permet généralement d'analyser de grandes quantités de données.
C'est pourquoi il est parfois assimilé au Big Data. Le Big Data se réfère toutefois principalement au traitement de bases de données volumineuses et à la manière dont la technologie le rend possible. Le Data Mining est quant à lui un outil permettant d'exploiter le Big Data. Il est lui-même appliqué à d'énormes bases de données afin d'obtenir des données structurées. Le data mining recherche donc des informations exploitables dans le pool de Big Data et crée ainsi des connaissances qui, sans une telle aide, seraient difficilement identifiables dans de grands ensembles de données.
Dans le domaine du commerce électronique, le data mining permet de faire des prévisions pertinentes sur le comportement des acheteurs et contribue ainsi à accroître le succès commercial. Cette technologie permet de tirer des conclusions sur le comportement d'achat des prospects et des clients à partir des achats passés. Les informations ainsi obtenues peuvent être utilisées dans presque tous les domaines du commerce en ligne : de l'acquisition de nouveaux clients à la communication parfaite avec les clients existants, en passant par des mesures après-vente efficaces.
Restez informé des dernières nouveautés en matière de personnalisation : inscrivez-vous à la newsletter Epoq. Inscrivez-vous dès maintenant!
Il devient ainsi de plus en plus facile d'aborder un acheteur ou un prospect de manière ciblée, comme s'il était bien connu de l'entreprise en tant que personne – c'est-à-dire en s'éloignant du groupe cible de clients pour se concentrer sur les besoins, les souhaits et les problèmes concrets d'un individu. La communication devient ainsi beaucoup plus ciblée et efficace. Cela est également rendu possible par les nombreuses interactions avec les clients dans le commerce électronique et par les données produits bien structurées dans les boutiques en ligne. En effet, elles permettent aux algorithmes d'être de plus en plus précis dans leurs modèles et les prévisions qui en découlent.
De nombreuses entreprises utilisent déjà aujourd'hui le data mining pour extraire des informations utiles de leurs données. Cette méthode apporte une aide précieuse dans les cas d'application suivants, par exemple :
Il existe plusieurs façons de reconnaître des modèles. La technologie détermine différentes approches en fonction de l'objectif visé.
Lors de la classification, les objets sont affectés à des classes en fonction de similitudes ou de modèles. Les applications concrètes sont les réseaux neuronaux, la classification bayésienne ou encore l'arbre de décision. Pour l'expliquer à l'aide d'un exemple compréhensible pour deux classes : le client est sensible à la nouvelle campagne « oui » ou « non ». Sur la base des données collectées lors des campagnes passées, un modèle est élaboré qui calcule l'affinité de chaque client sous forme de probabilité. Afin que chaque client puisse bénéficier de la meilleure campagne possible, cette méthode est répétée pour plusieurs campagnes.
Le regroupement et la segmentation des bases de données permettent de diviser les grandes quantités de données en groupes plus petits et homogènes sur la base de caractéristiques communes ou au moins similaires. Le défi particulier pour les analystes réside ici dans le fait que les algorithmes trouvent ces groupes sans connaissances préalables et que des analyses supplémentaires sont nécessaires pour que l'être humain puisse également reconnaître les similitudes. De plus, les similitudes ne sont pas toujours exploitables.
Restez informé des dernières nouveautés en matière de personnalisation : inscrivez-vous à la newsletter Epoq. Inscrivez-vous dès maintenant!
Les séquences récurrentes et les règles d'association ont pour but de mettre en évidence les liens. L'objectif est d'identifier et d'exploiter les combinaisons fréquentes. Elles sont utilisées dans le commerce électronique pour identifier et représenter les régularités dans le comportement des clients, par exemple SI (temps de chargement de la page > 2 secondes) ALORS (le client interrompt sa visite).
Dès l'année 2000, une norme uniforme a été créée pour les processus d'exploration de données : le modèle CRISP-DM (Cross Industry Standard Process for Data Mining) doit permettre aux entreprises de tous les secteurs d'utiliser plus rapidement des résultats plus précis, et ce dans tous les secteurs. Pour cela, ce processus standardisé est divisé en six phases. En fonction de la tâche à accomplir, l'accent est généralement mis plus ou moins fortement sur les différentes étapes. Leur ordre n'est en outre pas strict et il est tout à fait courant de passer d'une phase à l'autre.
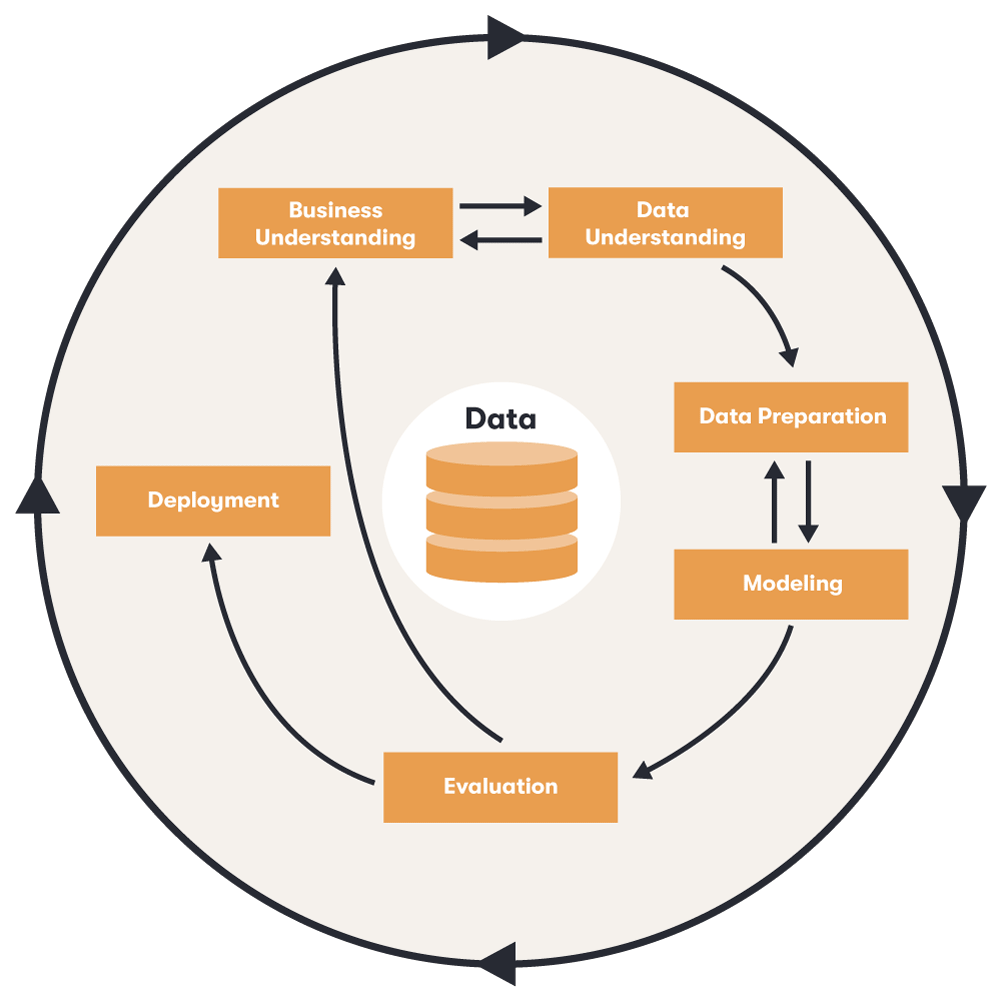
Le modèle CRISP-DM selon Shearer présente le processus standard intersectoriel pour l'exploration de données (source : représentation propre d'après Shearer¹)
L'objectif de cette étape est de décrire précisément le problème afin de formuler des exigences concrètes pour l'analyse des données. Cette première étape importante permet de définir des mesures et de vérifier que le processus permet d'atteindre les objectifs fixés.
Au cours de cette phase , les données sont collectées, décrites et vérifiées. Un analyste tente donc de trouver les bases de données appropriées et de comprendre leurs caractéristiques. Il doit analyser si la base de données est suffisante pour atteindre les objectifs de l'entreprise formulés lors de la première étape.
Les données sont désormais sélectionnées et nettoyées. Ces deux étapes sont nécessaires pour obtenir des résultats significatifs. De plus, les statisticiens transforment les données afin qu'elles puissent être présentées de manière pertinente et utilisées pour la modélisation.
Les analystes choisissent ensuite une technique de modélisation appropriée et vérifient à nouveau si la structure des données répond aux exigences de la modélisation. Ils créent un modèle test et en vérifient la qualité et la précision.
Le modèle testé est évalué en termes de résultats et de processus avant que l'entreprise ne le mette en œuvre. Si les objectifs du projet de data mining ne sont pas atteints, le chef de projet décide à quelle phase l'équipe de projet doit revenir. Si le modèle fait ses preuves, il est mis en œuvre.
Les connaissances acquises sont classées et traitées afin que l'entreprise puisse exploiter ces nouvelles informations.
Le data mining vous permet d'exploiter une mine d'informations auxquelles vous n'auriez pas accès autrement. Grâce à cette technologie, vous pouvez analyser les données de vos clients et, sur cette base, déterminer comment augmenter votre acquisition et votre fidélisation de clientèle. Il est toutefois important d'adopter une approche ciblée afin de tirer des conclusions fiables à partir des données.
Le data mining est le processus qui consiste à identifier automatiquement des modèles ou des corrélations dans des bases de données volumineuses et à les rendre exploitables, généralement à l'aide d'algorithmes spéciaux.
Le terme « Big Data » désigne principalement le traitement de grandes quantités de données et les technologies qui le rendent possible. Le Data Mining, quant à lui, est un outil d'analyse appliqué à ces données volumineuses afin d'y découvrir des modèles et des informations exploitables. Il permet d'extraire des données des connaissances qui seraient difficilement identifiables sans procédés automatisés.
Le data mining est utilisé, par exemple, pour les prévisions relatives à la valeur vie client, l'optimisation des ventes croisées et incitatives, la segmentation de la clientèle, l'optimisation des campagnes ou l'optimisation des prix.
Parmi les méthodes les plus importantes, on trouve la classification, l'analyse par grappes et les règles d'association. Elles classent les données, regroupent des objets similaires ou identifient des liens et des modèles dans les processus.
CRISP-DM (Cross Industry Standard Process for Data Mining) est un modèle intersectoriel en six phases qui standardise les processus d'exploration de données et les structure de manière personnalisable.
Vous souhaitez découvrir comment exploiter pleinement le potentiel de vos données ?
Regarde notre webinaire enregistré sur ce sujet !
