
5,04 % mehr Umsatz pro Session durch neue Personalisierungsstrategie bei Outletcity Metzingen
Outletcity Metzingen stellt die Personalisierungsstrategie auf den Prüfstand und steigert den Umsatz pro Session um 5,04 %.
Produktempfehlungen verfolgen das Ziel, passende Produkte auszuspielen, die den Kunden inspirieren und schlussendlich zu einem höheren Warenkorbwert führen. Um das zu erreichen werden selbstlernende Algorithmen und Regressionsbäume benötigt, die für jede individuelle Situation eine passenden Regel berechnen. Die Regelketten sollen dabei für die jeweiligen Situationen stets optimiert werden und somit mehr Umsatz bewirken. Wie das funktioniert, zeigen wir dir im dritten Teil unserer Blogreihe Reinforcement-Learning-Prozess.

Diese Inhalte erwarten dich in diesem Blogartikel:
Wie sieht eine Regel für Empfehlungen aus?
Regel-Generierung mit selbstlernenden Algorithmen über Regressionsbäume
Was ist ein Regressionsbaum?
Welche Daten nutzt ein Regressionsbaum zur Aufstellung von Empfehlungen?
Beispiel: Vorhersage der Markenanzahl am Beispiel Anna
Der Aufbau eines Regressionsbaum birgt Milliarden an Möglichkeiten
Die Entwicklung des Grundgerüsts eines Regressionsbaums
Fazit: Mit selbstlernenden Algorithmen und Regressionsbäumen zur Umsatzsteigerung
Zunächst möchten wir klären, wie der Agent vorgeht, um Regeln über selbstlernende Algorithmen für Empfehlungen genau zu definieren. Mit ihnen hat er Einfluss auf die E-Commerce Recommendations auf jeder neu aufgerufenen Seite eines Online-Shops.
Hierfür schauen wir uns an, wie eine Regel aus einem Regelsystem aussehen kann: “Zeige nur Produkte der x Marken, die sich der Kunde am häufigsten angeschaut hat”. Das x kann dabei die Werte 1, 2 oder 3 sowie ∞ annehmen. In diesem Fall bedeutet ∞, dass die Empfehlungen nicht auf bestimmte Marken eingeschränkt werden.
Nachdem eine Regel aufgestellt wurde, hat der Agent mit Hilfe von selbstlernenden Algorithmen die Aufgabe herauszufinden, wann welcher Wert von x am besten geeignet ist. Diese Entscheidung trifft der Agent anhand der individuell getrackten Userdaten. Das bedeutet, dass er sich bei markenaffinen Kunden anders entscheiden kann, als bei Kunden, bei denen keine Markenpräferenz erkennbar ist.
Bleibe up to date in Sachen Personalisierung: Melde dich zum Epoq Newsletter an. Jetzt anmelden!
Im Folgenden zeigen wir dir, nach welchem Modell selbstlernende Algorithmen Regeln aufstellen und wie unser Agent sie für relevante Empfehlungen nutzt.
Zunächst geht es darum, für unsere Beispiel-Regel zu der Anzahl der Marken den Wert x zu bestimmen. Das Ziel ist dabei, den höchstmöglichen Umsatz zu erreichen. Somit machen wir uns auf die Suche nach dem idealen Wert für x für jede einzelne Situation.
Zur Erreichung unseres Ziels erstellt der Agent einmal am Tag ein Machine-Learning-Modell. Mit ihm kann er vorhersagen, welche Werte in welchen Situationen am besten passen. Dafür wird eine Vorgehensweise benötigt, die anhand der Kundenhistorie den erwarteten Umsatz präzise vorhersagt. Für diese Vorhersagen gehören Regressionsbäume zu einem passenden Machine-Learning-Modell. Die Vorteile davon:
Das klingt soweit schonmal gut. Doch wie kann man sich jetzt einen Regressionsbaum vorstellen? Die Struktur ist ähnlich aufgebaut wie ein Kategoriebaum eines Online-Shops, mit dem die Produkte unterteilt werden. Hier kann man die Produktkategorien mehrfach unterteilen. So gehören Shirts und Blusen beide in die Kategorie Oberbekleidung. Shirts können jedoch nochmal detaillierter unterteilet werden, z. B. in Polo und Langarm.
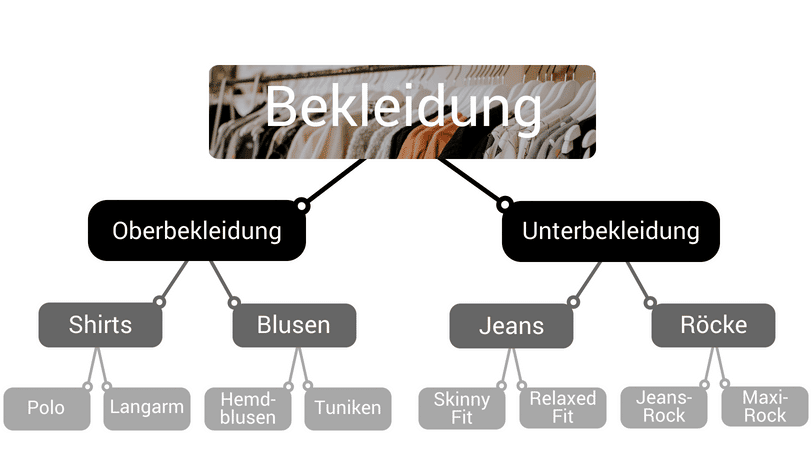
Beispielhafte Struktur eines Kategoriebaums für einen Online-Shop
Um herauszufinden, wie viele Marken angezeigt werden sollen, muss sich unser Agent am Regressionsbaum entlang hangeln. Dieser ist hier nicht nach Kleidungs-Kategorien unterteilt, sondern nach den aufgezeichneten Trackingdaten. Die einzelnen Daten bestehen aus einem Vektor mit Informationen über die Sessions eines Users. Das kann z. B. die Information zur Anzahl der verschiedenen Produktdetailseiten sein, die der Kunde gesehen hat. Auch die Information darüber, wie lange er bereits auf der Website ist, ob er sich eher hochwertige oder preiswerte Produkte anschaut, können mit einspielen. Dazu kommen noch Daten aus der Vergangenheit. Sie enthalten Informationen darüber, wie der Agent sich schonmal entschieden hat und für welchen Betrag der Kunde am Ende der Session eingekauft hat.
Gehen wir nun das Beispiel mit der Anzahl der Marken anhand dem unten abgebildeten Regressionsbaumes durch. Dafür betrachten wir Kundin Anna. Gerade hat sie eine Jacke aufgerufen, die 89,99€ kostet. Der Agent muss sich bei ihr entscheiden, wie viele Marken er empfiehlt, um den höchstmöglichen Umsatz zu generieren. Anna hat bereits sieben verschiedene Produktdetailseiten für zwei verschiedene Marken aufgerufen.
Aufgrund dieser Angaben müssen wir zunächst den rechten Zweig und anschließend den linken Zweig wählen. Bei der nächsten Entscheidung geht es um die Anzahl der angezeigten Marken. Dies ist ja gerade das, was der Agent noch nicht weiß, sondern untersuchen möchte. Er geht deshalb beiden Pfaden nach, um zu prüfen, was herauskommt. Auf der nächsten Ebene muss er sich wieder anhand der Anzahl der angezeigten Marken entscheiden. Diesmal sogar noch feingranularer. Auch hier verfolgt er wieder alle möglichen Abzweigungen.
Am Ende des Regressionsbaumes erhält er folgende Abschätzungen: Wenn er sich für genau eine Marke entscheidet, dann kann er für Kundin Anna mit einem durchschnittlichen Umsatz von 50,86€ rechnen. Wenn er sich hingegen für zwei verschiedene Marken entscheidet, kann er etwas mehr Umsatz, nämlich 53,48€, erwarten. Dies ist auch mehr als die 46,25€ bzw. 41,78€ für drei bzw. beliebig viele Marken. Der erwartete Umsatz ist also für zwei verschiedene Marken am höchsten. Dies ist dann auch die Entscheidung, die der Agent trifft. Anschließend können die tatsächlichen Empfehlungen für Anna berechnet und zu ihrem Browser gesendet werden.
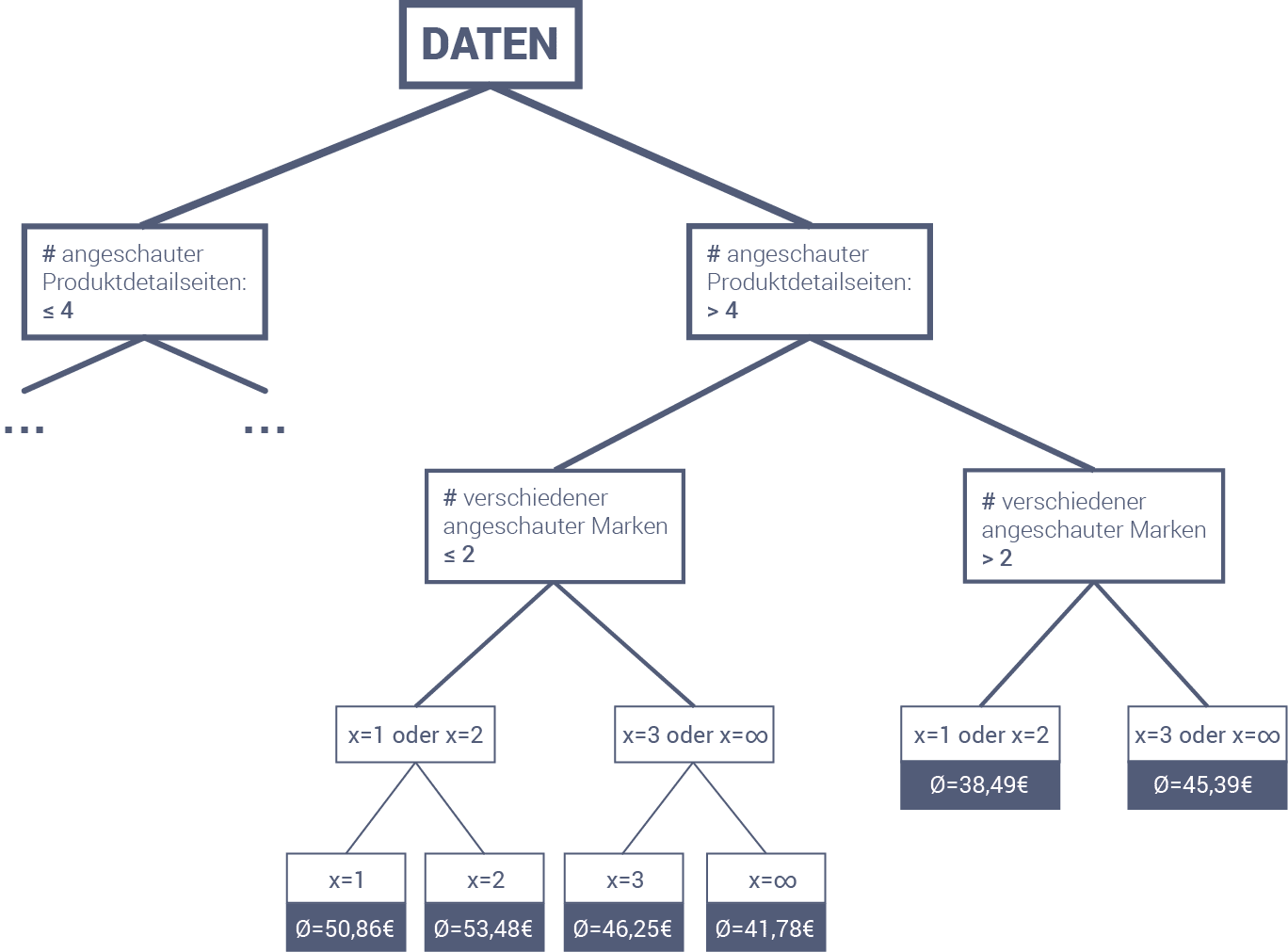
Das Beispiel mit Anna ist eine starke Vereinfachung. Die Bäume, die für Produktempfehlungen tatsächlich verwendet werden, sind sehr viel feingranularer. D.h. sie haben viel mehr Verzweigungen, gehen mehr in die Tiefe und betrachten mehr Features aus der jeweiligen Session. Dennoch benötigen die Server für das Durchsuchen des Baumes nur ein paar Millisekunden.
Als nächstes stellt sich hier die Frage, wie gut ein Regressionsbaum aufgebaut ist. Es gibt Milliarden über Milliarden Möglichkeiten die einzelnen Entscheidungen für den Baum zusammenzustellen. Nicht jede dieser Möglichkeiten ist gleich gut. Damit die Vorhersagen des Baumes zutreffend sind, muss der Baum gut aufgebaut sein. Wie gut ein Baum aufgebaut ist, können wir anhand historischer Kundendaten testen. Je besser der Baum ist, desto geringer sind die Abweichungen zwischen den tatsächlichen Umsätzen und denen, die vom Baum vorhergesagt wurden.
Bleibe up to date in Sachen Personalisierung: Melde dich zum Epoq Newsletter an. Jetzt anmelden!
Um möglichst gute Bäume zu erstellen, verwenden wir selbstlernende Algorithmen. D.h. wir erstellen die Entscheidungen für die Bäume anhand der gesammelten Sessiondaten und nicht aufgrund von menschlichen Meinungen. Dabei fangen wir zunächst mit einem leeren Baum an. Diesem fügen wir dann nach und nach eine Entscheidung hinzu. Eine Entscheidung besteht aus zwei Informationen. Zum einen muss man ein Feature (Anzahl gesehener Produktdetailseiten, Anzahl gesehener Marken, Zeit auf Website…) wählen, zum anderen eine Zahl c an der getrennt wird: alle Sessions mit einem Wert kleiner oder gleich c gehen nach links, alle anderen nach rechts.
Anschließend wird für jedes Feature berechnet, welcher c-Wert am besten dafür sorgt, dass die entstehenden Vorhersagen den tatsächlichen Umsätzen am nächsten sind. Dann kann man prüfen, für welches Paar von Feature und c-Wert dies am besten funktioniert und legt sich daraufhin auf ein Feature fest. Hat man nun auf diese Weise eine Entscheidung dem Baum hinzugefügt, kann man mit der nächsten Entscheidung weitermachen. Diese Prozedur setzt man soweit fort, bis der Baum ausreichend weit aufgebaut ist.
Für die Aufstellung von Regeln werden selbstlernende Algorithmen und das Modell der Regressionsbäume benötigt. Entscheidungsbäume bieten im Vergleich zu starren Strategien eine ideale Möglichkeit, auf die individuellen und sekündlich ändernden Situationen der Online-Shopper, einzugehen. Denn mit den Entscheidungsbäumen wird die vom Agenten zu treffende Entscheidung, abhängig vom derzeitigen Zustand des Online-Shoppers, getroffen. Zudem können die Entscheidungsbäume durch selbstlernende Algorithmen stets optimiert werden. So können Strategien verfolgt werden, die den maximalen Umsatzwert der jeweiligen Online-Shopper unterstützen zu erreichen.
Zum ersten Teil unserer Blogreihe “Reinforcement-Learning-Prozess”: Wie du Reinforcement Learning für deinen Online-Shop gewinnbringend einsetzt (Teil 1)
Und hier gehts zum zweiten Teil: Wie du mit Real Time Analytics die Kaufwahrscheinlichkeit erhöhst (Teil 2)
5,04 % mehr Umsatz pro Session: Die Outletcity Metzingen hat ihre Personalisierungsstrategie auf den Prüfstand gestellt.
Case Study jetzt anfordern!

Sie sehen gerade einen Platzhalterinhalt von Hubspot Embedded Content. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von HubSpot. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Hubspot Meetings. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen