
E-Book – Der digitale Verkäufer – Reinforcement Learning im E-Commerce
Erhalte umfassende Insights zum Einsatz von Reinforcement Learning zur Personalisierung von Online Shops.
Künstliche Intelligenz (KI) ist aus vielen Unternehmen nicht mehr wegzudenken. Sie hilft dabei, Prozesse zu automatisieren, Kunden neue Services anzubieten und Produkte weiterzuentwickeln. Im E-Commerce wird KI beispielsweise zur Personalisierung, in Form von Chatbots sowie in smarten Suchmaschinen eingesetzt. Eine Form künstlicher Intelligenz ist das Supervised Learning. Erfahre in unserem Artikel, was sich hinter diesem Modell verbirgt, wie es funktioniert und welche Vorteile und Herausforderungen es gibt.

Diese Inhalte erwarten dich in diesem Blogartikel:
Was ist Supervised Learning?
Wie funktioniert überwachtes Lernen?
Wann wird Supervised Learning eingesetzt?
Vorteile des KI-Modells
Herausforderungen in Bezug auf Supervised Learning
Andere Formen des Machine Learning
Fazit: Supervised Learning bietet Online Shops großes Potenzial
Häufige Fragen zu Supervised Learning
Supervised Learning heißt „Überwachtes Lernen“ und bezeichnet einen Ansatz zur Formung künstlicher Intelligenz (KI). Wie bei jeder Form des Machine Learning muss die KI mittels Algorithmen und statistischen Modellen trainiert werden, um aus einem bestimmten Datenset relevante Schlussfolgerungen zu ziehen. Neben dem Supervised Learning wird beim Machine Learning in Semi-Supervised Learning, Unsupervised Learning und Reinforcement Learning unterschieden. Alle diese Formen dienen dazu, neue Produkte, Prozesse und Services zu entwickeln oder sie zu verbessern.
Beim Supervised Learning trainieren Datenwissenschaftler einen Computer-Algorithmus und überwachen ihn während des Lernens. Sie versorgen ihn zunächst mit einer Vielzahl an Input-Daten, die jeweils ein Label für den erforderlichen Output tragen. Das Ergebnis ist also vorher bekannt. Der Algorithmus wird so lange trainiert, bis er die zugrunde liegenden Muster und Beziehungen zwischen Input und Output sicher erkennen kann.
Bleibe up to date in Sachen Personalisierung: Melde dich zum Epoq Newsletter an. Jetzt anmelden!
Dann durchläuft die Maschine eine Testphase mit Input-Daten ohne offensichtliches Label. Hier trifft sie selbst eine Entscheidung, welcher Output der richtige ist und vergleicht ihr Ergebnis mit demjenigen, das die Entwickler vorgegeben haben. Die Differenzen bzw. konkreten Vorhersagen werden für die Optimierung in der nächsten Lernphase genutzt. Die so gemessene Genauigkeit des Algorithmus zeigt also auf, wie gut dieser bereits gelernt hat und was im praktischen Einsatz zu erwarten ist. Das Ziel: Der Algorithmus soll möglichst passgenauen Output liefern, wenn er nach der Testphase mit unbekannten Daten ohne Label gefüttert wird.
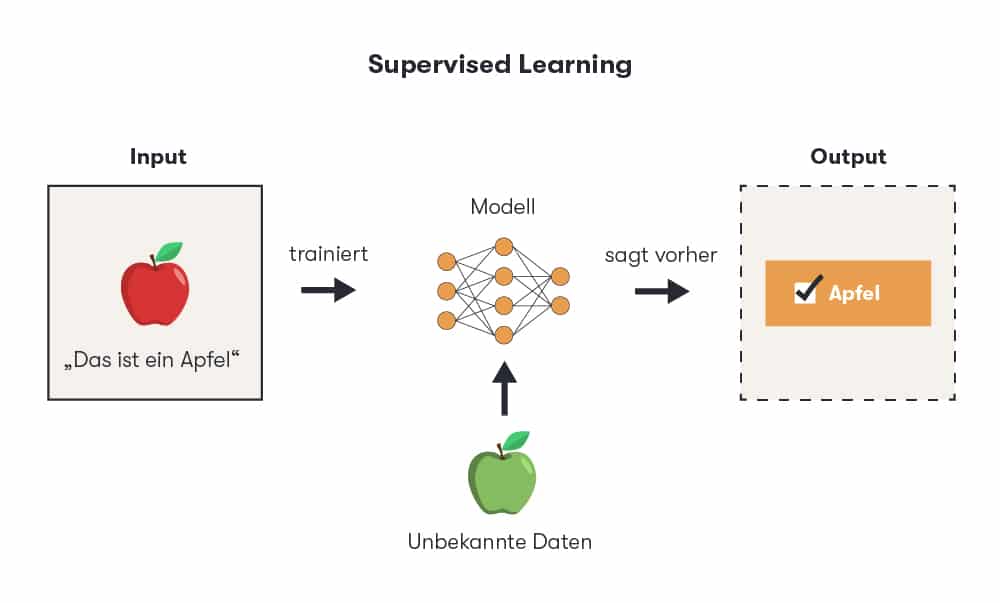
Diese Form der künstlichen Intelligenz wird bereits für zahlreiche Anwendungsfälle im E-Commerce eingesetzt. Sie eignet sich dabei insbesondere für Klassifikationen und Regressionsanalysen:
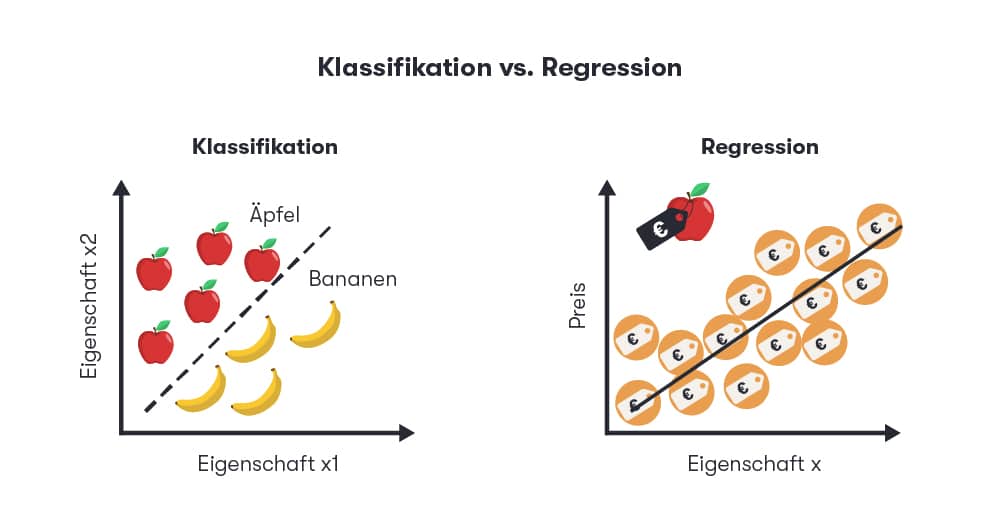
Supervised Learning hilft dabei, reale Probleme zu lösen, wie die Erkennung von Kreditkartenbetrug oder die Filterung von Spam, indem verschiedene Prozesse automatisiert werden. Das spart langfristig Zeit und Geld.
Auf der Grundlage früherer Erfahrungen kann die Maschine zukünftige Entwicklungen vorhersagen. Bei Spam erkennt sie beispielsweise bestimmte Wörter, die im E-Mail-Text, im Betreff oder in der Absenderadresse vorkommen. Das Trainieren der KI hilft dabei, eine genaue Vorstellung von den zu bewertenden Objektklassen zu erhalten. Langfristig kann so das zeitaufwendige Bewerten und Klassifizieren großer Datensätze automatisiert und vereinheitlicht werden. Eine gut trainierte KI übertrifft dabei die Performance eines menschlichen Bearbeiters und gibt damit nicht nur personelle Ressourcen frei, sondern reduziert auch die Fehleranfälligkeit.
Damit die Maschine Zusammenhänge verlässlich erkennt, müssen die Daten gut aufbereitet sein. Denn fehlerhafte Daten oder eine unzureichende Aufbereitung dieser stellen eine große Herausforderung dar. Unsupervised Learning “kompensiert” das dadurch, dass ein Mensch die Ergebnisse interpretiert, die Parameter adjustiert und neu berechnet. Da dies aber vorrangig manuell geschieht, zieht das einen hohen Zeit- und Kostenaufwand nach sich. Probleme in den Daten bzw. eine fehlende Aufbereitung dieser ist jedoch nicht nur eine Herausforderung für Supervised Learning, sondern auch für alle anderen Lernverfahren. Deep Learning kann dieses Problem in Teilen durch extrem viel Rechenzeit und Datenmenge kompensieren aber auch bei diesem Verfahren helfen gut aufbereitete Daten natürlich. Hier greift das Prinzip “Garbage In – Garbage Out”, denn der Output hängt maßgeblich von den hinein gegebenen Daten ab.
Gibt es Dopplungen, fehlende Inhalte oder fehlende Verknüpfungen im Datensatz, weiß die KI nichts damit anzufangen. Gleiches gilt, wenn sich die Testdaten vom Trainingsdatensatz unterscheiden. Die Maschine darf nämlich nicht zu genau auf die Trainingsdaten angelernt sein. Sonst tritt der Effekt des sogenannten Overfitting ein: Nur, wenn ein Daten-Input exakt mit den vorgegebenen Variablen übereinstimmt, kann er in die entsprechende Kategorie eingeordnet werden. Auch mit dieser Herausforderung ist nicht ausschließlich das Supervised Learning konfrontiert. So ist auch Deep Learning nicht gefeit vor diesem Effekt.
Des Weiteren sind vielfältige Daten wichtig, damit die Maschine möglichst viele unterschiedliche Szenarien bewerten kann. Wenn sie beispielsweise lernen soll, Menschen und Tiere auf Bildern zu unterscheiden, sollten als Tiere nicht nur Hunde, sondern auch Giraffen, Elefanten oder Gorillas zu sehen sein. Die Datenwissenschaftler benötigen also genügend Wissen über die verschiedenen Objektklassen, um sie für die KI klar herauszuheben.
Das Reinforcement Learning ist ebenfalls von den genannten Problemen betroffen, aufgrund der Art des Lernens teilweise sogar noch um ein Vielfaches stärker.
Neben dem Supervised Learning gibt es wie erwähnt drei weitere Formen des Machine Learning: Unsupervised Learning, Semi-Supervised Learning und Reinforcement Learning.
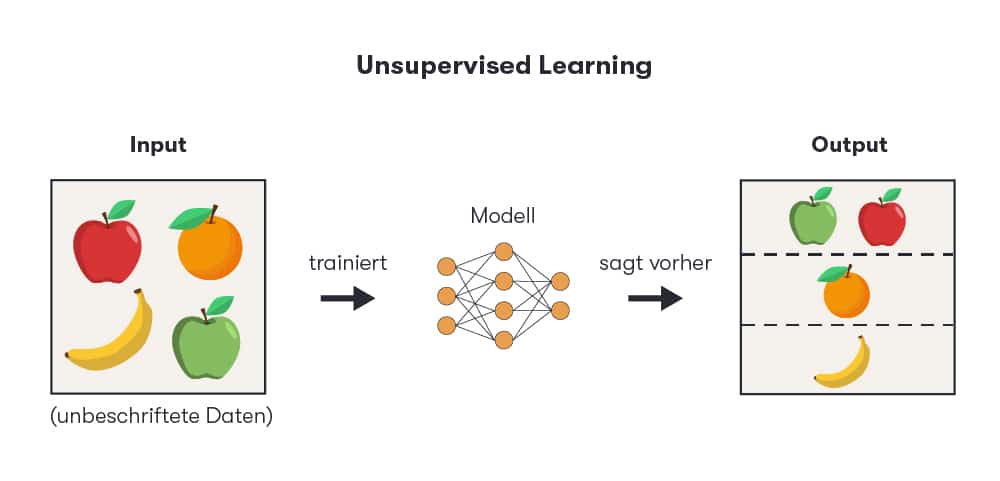
Beim Unsupervised Learning erhält die Maschine Daten, die zuvor nicht mit einem Label versehen wurden. Die KI soll selbst herausfinden, welche Muster und Ähnlichkeiten zwischen den Daten bestehen. Hierfür benötigt sie eine ausreichend große Anzahl an Daten – viel mehr als beim Supervised Learning –, um diese verlässlich clustern und logische Schlussfolgerungen ziehen zu können.
Ein Beispiel für den Einsatz dieser Form der künstlichen Intelligenz ist die Bildung von Segmenten zur Zielgruppenanalyse. Diese kann wiederum genutzt werden, um personalisierte Inhalte für verschiedene Segmente auszuspielen.
Das Semi-Supervised Learning ist eine Mischform zwischen beiden. Während des Trainings erhält die Maschine Datensätze sowohl mit Label als auch solche ohne. Diese Form des Machine Learning eignet sich in Fällen, in denen nicht ausreichend qualitative Daten mit Label zur Verfügung stehen. Ein typisches Anwendungsbeispiel ist die Gesichtserkennung. Es genügt, eine bestimmte Person auf einigen Bildern zu taggen, damit die KI selbstständig andere Bilder findet, auf denen diese Person abgebildet ist.
Bleibe up to date in Sachen Personalisierung: Melde dich zum Epoq Newsletter an. Jetzt anmelden!
Beim Modell des Reinforcement Learning – auf Deutsch “Verstärkendes Lernen” – nutzen die Datenwissenschaftler Belohnungen und Bestrafungen, um der künstlichen Intelligenz ein bestimmtes Verhalten beizubringen. Der Algorithmus erlernt durch Ausprobieren selbstständig eine Strategie mit dem Ziel, die Belohnungen zu maximieren. Ursprünglich zum Erlernen von Brettspielen eingesetzt, optimiert das verstärkende Lernen heutzutage zahlreiche Prozesse im E-Commerce. Wenn du mehr über Reinforcement Learning erfahren möchtest, lies gerne unsere Blogartikel-Reihe zum Reinforcement-Learning-Prozess.
Künstliche Intelligenz kannst du auf vielfältige Weise in deinem Online Shop anwenden, um deine Kunden für deine Marke zu begeistern und höhere Umsätze zu generieren. Für den jeweiligen Anwendungsfall ist es notwendig, das passende KI-Modell auszuwählen. Supervised Learning verfügt über großes Potenzial, die Prozesse und Produkte in deinem Online Shop zu optimieren. Nutze KI, um deine E-Mails im Kundenservice zu filtern, deinen Kunden personalisierte Inhalte anzubieten oder Prognosen über zukünftige Umsätze zu erhalten.
Supervised Learning ist eine Form des Machine Learning und wird mit „Überwachtes Lernen“ übersetzt. Datenwissenschaftler trainieren dabei eine Maschine, Zusammenhänge zwischen Daten zu erkennen und daraus Schlussfolgerungen zu ziehen. Das Ergebnis ist dabei jeweils im Vorhinein bekannt, sodass die KI durch den Abgleich zwischen Rechenergebnis und Vorgabe lernen kann, besser zu werden. Beispiel: das Herausfiltern von Spam aus eintreffenden E-Mails.
Beim Supervised Learning wird ein Computer-Algorithmus zunächst mit vorbereiteten Datensets trainiert. Jeder Input trägt ein Label für den erforderlichen Output (Ergebnis). Anschließend durchläuft das KI-Modell eine Testphase mit weiteren Daten, bis der Output möglichst genau den erforderlichen Ergebnissen entspricht.
Diese Form künstlicher Intelligenz eignet sich besonders für Klassifikationen und Regressionsanalysen, also der Suche nach leicht nachvollziehbaren Zusammenhängen zwischen Variablen. Sie hilft dabei, reale Aufgabenstellungen wie die Kategorisierung von Blogartikeln oder das Erkennen von Kreditkartenbetrug zu lösen.
Das Trainieren der künstlichen Intelligenz ist mit einem hohen manuellen Aufwand und viel Zeit verbunden. Die Daten müssen gut aufbereitet, vielfältig und in ihren Zusammenhängen klar definiert sein.
Beim Supervised Learning wird der Algorithmus mit gekennzeichneten Daten gefüttert, damit die künstliche Intelligenz die Muster in den Datensätzen erkennt. Beim Unsupervised Learning tragen die Daten kein Label. Die KI muss also selbst Zusammenhänge zwischen den einzelnen Variablen herstellen. Semi-Supervised Learning vereint beide Formen: Ein Teil der Daten trägt ein Label, der Rest nicht.
Du möchtest mehr über Reinforcement Learning im E-Commerce erfahren?
Dann hol dir unser E-Book zum Thema!

Sie sehen gerade einen Platzhalterinhalt von Hubspot Embedded Content. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von HubSpot. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Hubspot Meetings. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen