
5,04 % mehr Umsatz pro Session durch neue Personalisierungsstrategie bei Outletcity Metzingen
Outletcity Metzingen stellt die Personalisierungsstrategie auf den Prüfstand und steigert den Umsatz pro Session um 5,04 %.
Im zweiten Teil unserer Reihe über unseren Reinforcement-Learning-Prozess gehen wir darauf ein, wie wir Real Time Analytics verwenden, um die Surfhistorie eines Online-Shop-Benutzers so aufzubereiten, dass der Agent damit arbeiten und gute Entscheidungen treffen kann. Hier steht er vor der Herausforderung in kurzer Zeit relevante Informationen aus der Menge aller gesammelten Daten herauszufiltern, um diese für Empfehlungen nutzen zu können.

Diese Inhalte erwarten dich in diesem Blogartikel:
Real Time Analytics kurz zusammengefasst
Real Time Analytics für den Einsatz in Online Shops
Datensammlung und -anreicherung
Einfluss bisheriger Anfragen
Einfluss durch den Faktor Zeit
Vergleich mit anderen Kunden
Informationen zum Verhalten auf Seiten ohne Empfehlungen
Von Big Data zu Smart Data für die Ermöglichung von Real Time Analytics
Smart Data in Real Time zusammenstellen
Unser Fazit zu Real Time Analytics für eine erhöhte Kaufwahrscheinlichkeit
Beim Real Time Analytics werden in einem Computersystem ankommende Daten direkt analysiert und weiterverarbeitet. Meist dient dies dazu, Menschen dabei zu unterstützen, Entscheidungen innerhalb weniger Minuten oder Sekunden zu treffen. Es kann sogar auch genutzt werden, um automatisierte Entscheidungen innerhalb weniger Sekunden oder Millisekunden (z. B. Entscheidung, welcher Content für einen User ausgegeben werden soll, der gerade die Webseite aufruft) zu treffen. Für ein Real Time System ist es besonders wichtig, dass die Analyseergebnisse schnell genug erstellt werden, damit auch die verbundenen Entscheidungen schnell durchgeführt werden können.
Bleibe up to date in Sachen Personalisierung: Melde dich zum Epoq Newsletter an. Jetzt anmelden!
Für relevante Empfehlungen in einem Online Shop soll unser Agent in Echtzeit automatisierte Entscheidungen treffen. Wenn ein Online Shopper eine Seite aufruft, auf der ein Empfehlungswidget eingebunden ist, so wird eine Anfrage an unseren Server gesendet. Der Server interpretiert die Anfrage und erstellt einen Zahlenvektor (Abb. 1) mit Informationen zum Aufruf für den Agenten. Anhand des Zahlenvektors entscheidet sich der Agent für eine oder mehrere Aktionen (z. B. Stelle den Preisbereich der E-Commerce-Recommendations auf 40€ bis 60€). Diese Entscheidungen nehmen Einfluss auf die Regelkette, mit der die tatsächlich zu empfehlenden Produkte bestimmt werden. Diese Produkte werden dann an den Browser des Benutzers zurückgegeben. Dort werden dann die Produkte im Widget angezeigt. Dieser gesamte Prozess dauert nur ein paar Millisekunden.
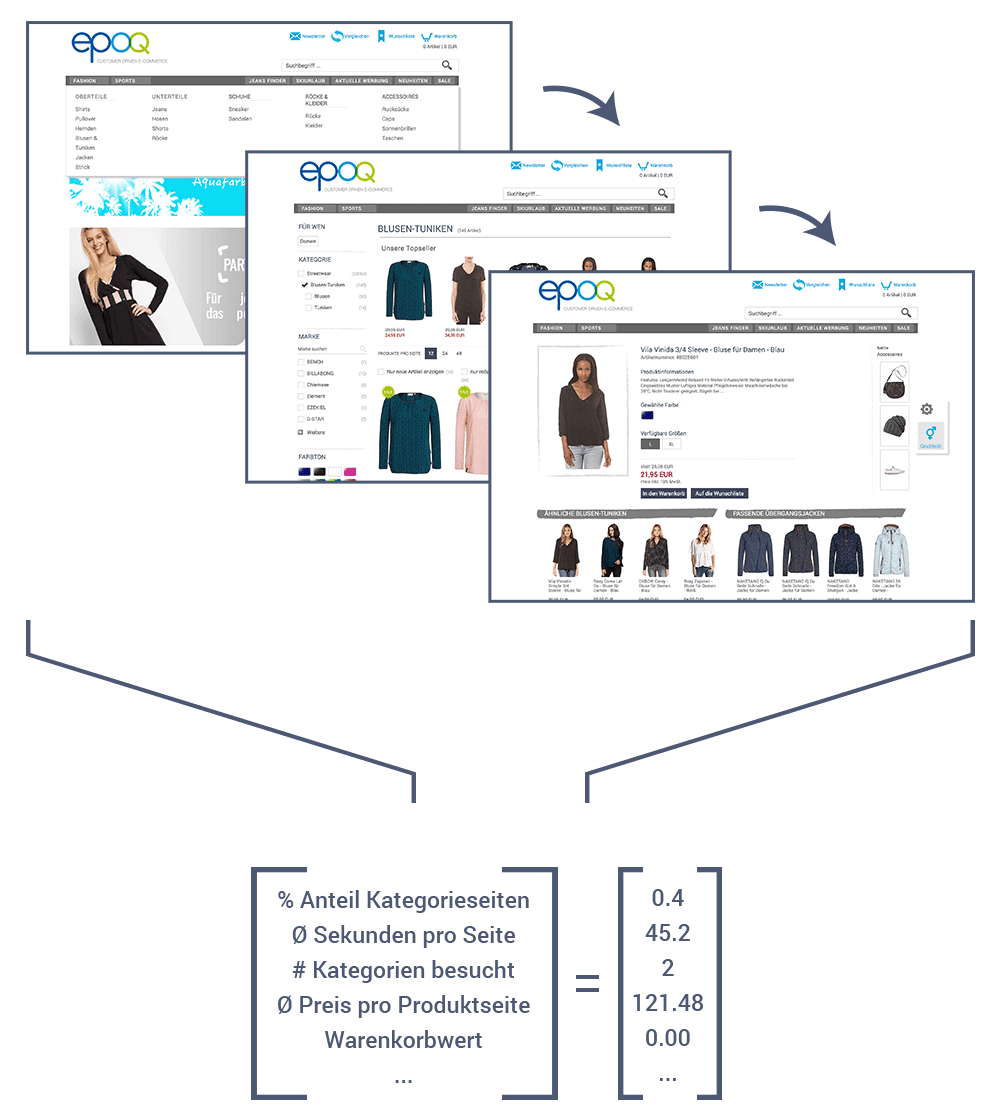
Abb. 1: Zahlenvektor mit Informationen zum Aufruf
Jetzt stellt sich natürlich die Frage, wie der Server die Anfrage interpretiert und den Zahlenvektor für den Agenten erstellt. Hier stellt sich die Herausforderung, möglichst viele sinnvolle Informationen zu erhalten und gleichzeitig innerhalb der geringen vorgegebenen Zeit diese zu berechnen.
Wenn der Browser das Empfehlungswidget anfragt, sendet er Parameter für den Aufruf an unseren Server. Diese Parameter beinhalten die Session-ID des Online Shoppers und Informationen über die Seite, die angefragt wird, z. B. die ID eines Produktes auf einer Produktdetailseite. Der Server hält weitere Daten im Arbeitsspeicher durch unsere Wissensbasis bereit, mit denen er die Aufrufdaten anreichern kann. Diese Daten bezieht er aus dem Produktkatalog und kann so zusätzliche Daten zu dem angefragten Produkt hinzufügen. Dies können einfache Einträge wie
sein.
Der Server hat auch die bisherigen Anfragen der Session und die zugehörigen Produkt-IDs im Arbeitsspeicher. Somit kann er Statistiken über alle angeschauten Produkte hinzufügen, z. B.:
Zusätzlich kann mit einbezogen werden, ob sich der Nutzer immer hochpreisige Produkte anschaut oder nur Produkte von einer geringen Anzahl von Marken oder ob mit späterem Aufrufen der Anteil von rabattierten Artikeln steigt.
Am letzten Beispiel sieht man, hier werden nicht nur Daten zum durchschnittlichen Verhalten des Users gesammelt, sondern auch Änderungen im Verhalten. Dies ist wichtig, weil viele Benutzer weiterhin durch die Webseite surfen, nachdem sie ihr gesuchtes Produkt gefunden haben. Allerdings verhalten sie sich dann anders (Wie? Z. B. von zielgerichtet zu stöbernd). Der Server speichert bei jeder Anfrage neben der Produkt-ID auch noch den genauen Zeitpunkt, zu dem die Anfrage auf dem Server angekommen ist. Daraus leitet er wiederum einige Dinge ab, wie etwa:
Diese Beobachtungen vergleicht der Server auch mit anderen Kunden. Dabei konnten folgende Erkenntnisse gewonnen werden:
Deshalb verknüpft der Server auch die Uhrzeit und den Wochentag mit den bisher erstellten Daten.
Wenn jeder Webseitenaufruf eines Benutzers an den Server übermittelt wird, auch wenn sich auf der Webseite kein Empfehlungswidget befindet, wie etwa auf Kategorieübersichtsseiten oder Informationsseiten zum Porto, dann verknüpft der Server auch diese Daten. So beobachtet er, ob der Benutzer häufig auf die vorhergehende Seite zurückgeht und berechnet den Anteil der Zeit, die sich der Benutzer auf Kategorieseiten bzw. Produktdetailseiten befunden hat.
Der Server hat auch sehr gute Möglichkeiten die Daten weiter anzureichern, wenn Cookies ordentlich getrackt und wiederkehrende Benutzer so erkannt werden. Dadurch können die gewonnen Daten in ein Verhältnis mit der jeweiligen Historie gesetzt werden. An dieser Stelle könnten wir noch viele weitere mögliche Datenbeobachtungen nennen, jedoch wird die Liste dann deutlich zu lang.
Die Anzahl der Datenpunkte die der Server so sammeln kann, ist enorm. So kommen schnell mal mehrere tausend einzelne Daten für eine einzige Abfrage der Empfehlungen zusammen. Es gibt mehrere Gründe dafür, dass es keine gute Idee ist, dass der Agent alle Daten verarbeitet. Vor allem benötigt der Server dafür mehr Zeit. Unser Ziel ist es allerdings, Empfehlungen in Echtzeit auszuspielen.
Bei zu vielen Daten kann es dem Agenten zudem schwer fallen, wichtige Muster in den Daten zu erkennen. Um zu verstehen warum das so ist, gehen wir noch einmal auf das Beispiel von unserem ersten Teil der Blogreihe zurück, bei dem wir unserem Hund Benno das Apportieren eines Balles beibringen.
Man könnte das Training auf einem freien Platz in einer Fußgängerzone ausprobieren. Allerdings wird es hier sehr schwer werden, dem Hund beizubringen, dass er dem geworfenen Ball hinterher rennen soll. Auf den Hund prasseln sehr viele Reize ein. Die vielen Besucher, denen er ausweichen muss, der Duft der Currywurst-Buden, das Jubeln und Schreien der Kinder und nicht zuletzt die reizenden Hündinnen, die viel interessanter sind als ein komischer Ball, der wegfliegt. Der Hund schafft es so nicht, sich auf das Wesentliche zu konzentrieren.
Ähnliches passiert bei unserem Reinforcement-Learning-Agenten. Gibt man ihm zu viele Daten zum Lernen, kann es schwierig werden, die wichtigen Muster von den weniger wichtigen Mustern zu unterscheiden.
Geht man nun mit dem Hund von der Fußgängerzone in den Park, so können hier immer noch viele Reize auftreten, die das Trainieren erschweren. Besonders bei Jagdhunden kann es passieren, dass sie die Freude auf das Hinterherlaufen nicht nur bzgl. des Balls entwickeln, sondern auf alles, was sich schnell von ihnen entfernt, wie Eichhörnchen, Fahrradfahrer oder Hummeln. Sie rennen dann auch diesen hinterher.
Auch beim Trainieren des Agenten können solche Effekte auftreten. So könnten sich Kunden hochpreisige Produkte in der Tierfutterkategorie anschauen und dabei Fußbälle aus dem Preisbereich 30€ – 50€ empfohlen bekommen. Zu diesem Zeitpunkt könnte viel Umsatz generiert werden. Das kann allerdings auch nur zufällig passieren und dieses Mal kein Muster darstellen, welches der Agent lernen soll. In diesem Fall würde der Agent fälschlicherweise lernen, unseren Tierfreunden Fußbälle im mittleren Preissegment zu empfehlen. Je mehr Daten dem Agenten zum Trainieren gegeben werden, desto höher ist die Gefahr, dass solch zufällige Muster darin vorkommen.
Den negativen Auswirkungen von zu vielen Reizen bzw. zu vielen Daten im Training kann entgegengewirkt werden, indem man die Reize und Daten auf geschickte Weise verringert.
Ein Hund macht mehr Fortschritte, wenn das Training in einem Raum stattfindet, der möglichst reizarm ist. Es laufen keine Eichhörnchen durchs Zimmer, Fernseher und Radio sind ausgeschalten und in der Küche wird gerade kein interessant duftendes Essen zubereitet. Hier kann sich der Hund viel besser auf den Ball und die Gestik des Trainers konzentrieren.
Auch für unseren Reinforcement-Agenten machen wir das Lernen einfacher, indem wir nur die hilfreichen Daten herausfiltern. Nebenbei stellen wir sicher, dass die Abfrage der Empfehlungen in Real Time abgearbeitet werden kann. Mit einfachen statistischen Verfahren bestimmen wir, wie gut die einzelnen Daten Käufe im Shop vorhersagen. Außerdem bestimmen wir, welche Daten zusammengenommen die vielfältigsten Informationen liefern.
Haben wir für einen Benutzer z. B. die vier Daten
dann sehen wir, dass die ersten drei statistisch miteinander korrelieren. Wenn wir die Anzahl der Daten auf drei verringern wollen, indem wir ein Datum rausfiltern, dann würden wir dafür eines der ersten drei Daten wählen, weil das letzte mehr Vielfalt in die Daten bringt. Wir würden heraussuchen, welches der ersten drei statistisch am wenigsten Aussagekraft für die Vorhersage der Käufe hat. Diese Analyse machen wir bei tausenden von Daten, solange bis nur noch ca. 60 bis 100 übrig bleiben.
So kann z. B. die Information, ob der Benutzer länger oder kürzer als andere Benutzer auf der Hauptseite ist, nicht in jedem Fall für eine Vorhersage genutzt werden.
Bleibe up to date in Sachen Personalisierung: Melde dich zum Epoq Newsletter an. Jetzt anmelden!
Das Filtern an sich benötigt ebenfalls Zeit. Wenn eine Anfrage an den Server gesendet wird, würde es zu lange dauern, erst alle Daten zu berechnen und danach noch zu bestimmen, welche Daten wieder herausgefiltert werden sollen. Stattdessen sollte einmal am Tag berechnet werden, welche Daten behalten werden sollen. Gelangt nun eine Anfrage an den Server, dann checkt dieser, welche Daten tatsächlich benötigt werden und berechnet nur diese. Damit schafft er es den Input für den Agenten in nur wenigen Millisekunden fertig zu stellen.
Um relevante Empfehlungen in Echtzeit ausspielen zu können, ist Data-Science-Know-how gefragt! Es müssen zum einen möglichst viele Daten gesammelt, angereichert und anschließend interpretiert werden. Zum anderen muss die Masse an Informationen auf die wirklich aussagekräftigen reduziert werden, sodass eine Ausspielung in Echtzeit möglich ist. Wir finden: Dieser Prozess lohnt sich, um durch die relevanten Empfehlungen Warenkörbe zu füllen und Online Shopper glücklich zu machen.
Zum ersten Teil unserer Blogreihe “Reinforcement-Learning-Prozess”: Wie du Reinforcement Learning für deinen Online-Shop gewinnbringend einsetzt (Teil 1)
Und hier gehts zum dritten Teil: Wie du durch selbstlernende Algorithmen deinen Umsatz steigerst (Teil 3)
5,04 % mehr Umsatz pro Session: Die Outletcity Metzingen hat ihre Personalisierungsstrategie auf den Prüfstand gestellt.
Case Study jetzt anfordern!

Sie sehen gerade einen Platzhalterinhalt von Hubspot Embedded Content. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von HubSpot. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Hubspot Meetings. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen