
How-To | Data Enrichment – Sorge für zielgenaue Entscheidungen (#epoqPXD22)
In diesem Slot zeigen die Speaker, verschiedene Lösungen zum Thema Datenmanagement.
Gut laufende Online Shops produzieren Unmengen an Daten. Um diese zu nutzen und in verwertbares Wissen umzuwandeln, nutzt Data Mining selbstlernende Algorithmen. Sie finden Muster, von denen Unternehmen viel über ihre Kunden lernen können. Erfahre hier, was Data Mining ist, wie es funktioniert und wie du es gewinnbringend für dich einsetzen kannst.

Diese Inhalte erwarten dich in diesem Blogartikel:
Data Mining Definition und Abgrenzung zu Big Data
Wichtige Vorteile von Data Mining im E-Commerce
Anwendungsbeispiele von Data Mining im Online-Handel
Diese Data-Mining-Methoden gibt es
Klassifikation auf der Basis von Eigenschaften
Gruppierung durch Cluster-Analyse und Segmentierung
Abhängigkeiten durch Assoziationsregeln und Sequenzen entdecken
CRISP-DM: Ein standardisierter Workflow
1. Aufgabendefinition: Business Understanding
2. Auswahl der relevanten Datenbestände: Data Understanding
3. Daten aufbereiten: Data Preparation
4. Auswahl und Anwendung von Data-Mining-Methoden: Modeling
5. Bewertung und Interpretation der Ergebnisse: Evaluation
6. Anwendung der Ergebnisse: Deployment
Fazit: Finde mit Data Mining heraus, was deine Kundendaten verraten
Data Mining beschreibt den Versuch, in Daten Muster zu finden und nutzbar zu machen. Diese Muster oder empirische Zusammenhänge sollen dabei möglichst automatisiert durch Algorithmen erkannt werden. Üblicherweise werden so große Datenmengen analysiert.
Deswegen wird es gelegentlich mit Big Data gleichgesetzt. Big Data bezieht sich jedoch primär auf die Verarbeitung umfangreicher Datenbestände und wie Technik diese ermöglicht. Data Mining ist hingegen ein Werkzeug, um Big Data nutzbar zu machen. Es wird selbst auf riesige Datenbanken angewendet, um strukturierte Daten zu erhalten. Data Mining sucht also in dem Big Data Pool nach verwertbaren Informationen und schafft so Wissen, das ohne derartige Hilfe in großen Datensätzen kaum noch zu erkennen ist.
Data Mining kann im E-Commerce treffende Voraussagen in Bezug auf das Käuferverhalten ermöglichen und somit zu mehr Erfolg beitragen. Die Technologie ermöglicht es, aus vergangenen Käufen Rückschlüsse auf das Kaufverhalten von Interessenten und Kunden zu ziehen. So gewonnene Erkenntnisse lassen sich in nahezu allen Bereichen des Online-Handels nutzen: Von der Neukundengewinnung über die perfekte Ansprache von Bestandskunden bis hin zu effizienten After-Sales-Maßnahmen.
Bleibe up to date in Sachen Personalisierung: Melde dich zum epoq Newsletter an. Jetzt anmelden!
Es wird dadurch immer leichter, einen Käufer oder Lead gezielt so anzusprechen, als wäre er dem Unternehmen als Person gut bekannt – weg also von der Kundenzielgruppe hin zu den konkreten Bedürfnissen, Wünschen und Problemen eines Einzelnen. Dadurch wird die Kommunikation erheblich zielgerichteter und erfolgreicher. Möglich wird das auch durch die vielen Kundeninteraktionen im E-Commerce sowie gut strukturierte Produktdaten in Online Shops. Denn sie ermöglichen es, dass Algorithmen in ihren Mustern und den daraus abgeleiteten Prognosen immer genauer werden.
Viele Unternehmen verwenden heute bereits Data Mining, um dadurch Wissenswertes aus ihren Daten zu extrahieren. Wichtige Hilfestellungen liefert die Methode beispielsweise bei den folgenden Anwendungsfällen:
Muster zu erkennen, ist auf verschiedenen Wegen möglich. Die Technologie entscheidet nach der Zielsetzung unterschiedliche Vorgehensweisen.
Bei der Klassifikation werden Objekte anhand von Ähnlichkeiten oder Mustern Klassen zugeordnet. Konkrete Umsetzungen sind neuronale Netze, Bayes-Klassifikation oder auch der Entscheidungsbaum. Um es mit einem verständlichen Beispiel für zwei Klassen zu erklären: Kunde ist affin für neue Kampagne “ja” oder “nein”. Basierend auf gesammelten Kampagnendaten der Vergangenheit wird ein Modell gelernt, das für alle Kunden die Affinität als Wahrscheinlichkeit berechnet. Damit am Ende jedem Kunden die beste Kampagne ausgespielt werden kann, wird diese Methode für mehrere Kampagnen wiederholt.
Gruppierungen und Segmentierungen in Datenbeständen helfen dabei, die großen Datenmengen anhand von gemeinsamen oder zumindest ähnlichen Eigenschaften in kleinere und homogene Gruppen einzuteilen. Die besondere Herausforderung für Analysten ist hierbei, dass Algorithmen diese Gruppen ohne Vorwissen finden und zusätzliche Analysen notwendig sind, damit auch der Mensch die Ähnlichkeiten erkennt. Zudem sind die Ähnlichkeiten nicht immer verwertbar.
Bleibe up to date in Sachen Personalisierung: Melde dich zum epoq Newsletter an. Jetzt anmelden!
Wiederkehrende Abfolgen und Assoziationsregeln sollen Zusammenhänge sichtbar machen. Ziel dabei ist es, häufige Kombinationen zu erkennen und zu verwerten. Sie werden im E-Commerce eingesetzt, um Regelmäßigkeiten im Kundenverhalten zu erkennen und darzustellen, z. B. WENN (Ladezeit Seite > 2 Sekunden) DANN (Kunde bricht Besuch ab).
Bereits im Jahr 2000 wurde ein einheitlicher Standard für Data-Mining-Prozesse geschaffen: Das CRISP-DM Modell (Cross Industry Standard Process for Data Mining) soll Unternehmen aus allen Branchen ermöglichen, präzisere Ergebnisse schneller und branchenübergreifend nutzen zu können. Dafür ist dieser standardisierte Ablauf in sechs Phasen gegliedert. Üblicherweise wird der Fokus je nach Aufgabenstellung mehr oder weniger stark auf die jeweiligen Etappen gelenkt. Ihre Abfolge ist zudem nicht strikt und es ist durchaus üblich, zwischen den einzelnen Phasen zu wechseln.
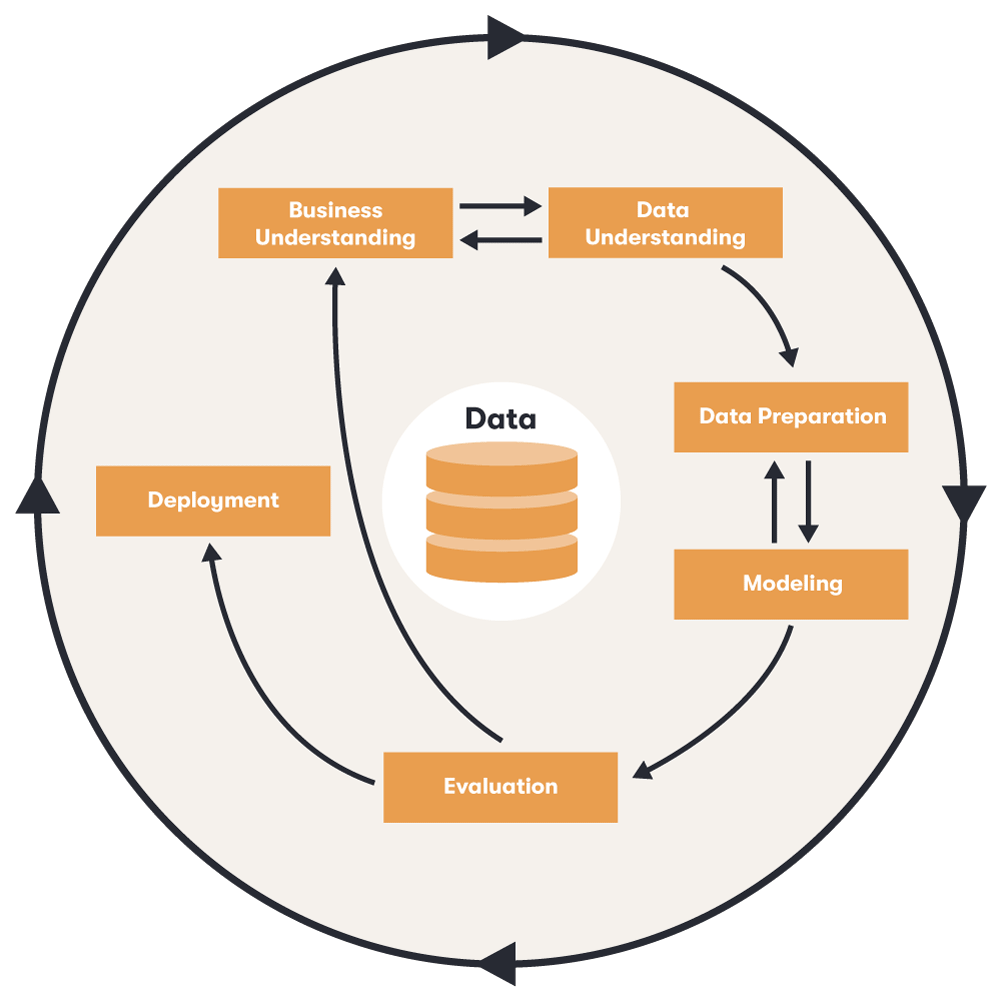
Das CRISP-DM Modell nach Shearer zeigt den branchenübergreifenden Standardprozess für Data Mining (Quelle: Eigene Darstellung nach Shearer¹)
Ziel dieses Stadiums ist es, die Problemstellung genau zu beschreiben, um damit konkrete Anforderungen an die Datenanalyse zu formulieren. Der wichtige erste Schritt hilft dabei, Maßnahmen festzulegen und den Prozess auf die Zielerfüllung zu prüfen.
In dieser Phase werden Daten gesammelt, beschrieben und geprüft. Ein Analyst versucht also, passende Datenbanken zu finden und sie und ihre Eigenschaften zu verstehen. Er muss analysieren, ob die Datengrundlage hinreichend ist, um die im ersten Schritt formulierten Unternehmensziele zu erreichen.
Die Daten werden nun selektiert und bereinigt. Beides ist notwendig, um aussagekräftige Ergebnisse zu erhalten. Außerdem transformieren Statistiker die Daten so, dass sie sinnvoll dargestellt und für die Modellierung genutzt werden können.
Nun wählen Analysten eine geeignete Modellierungstechnik und gleichen erneut ab, ob die Datenstruktur den Anforderungen der Modellierung gerecht wird. Sie erstellen ein Testmodell und prüfen so die Qualität und Genauigkeit.
Das Testmodell wird hinsichtlich der Resultate und des Prozesses bewertet, bevor das Unternehmen es einsetzt. Bleiben die Ziele des Data-Mining-Projekts unerreicht, entscheidet der Projektleiter, zu welcher Phase das Projektteam zurückkehrt. Behauptet sich das Modell, wird es eingeführt.
Die gewonnenen Erkenntnisse werden geordnet und aufbereitet, sodass das Unternehmen das neue Wissen nutzen kann.
Data Mining ermöglicht dir, einen Wissensschatz zu heben, an den du sonst nicht gelangst. Durch diese Technologie kannst du deine Kundendaten analysieren und auf dieser Grundlage herausfinden, wie du die Kundengewinnung und -bindung erhöhst. Wichtig ist jedoch ein zielgerichtetes Vorgehen, um belastbare Schlüsse aus den Daten zu ziehen.
Data Mining ist der Prozess, in umfangreichen Datenbeständen automatisch Muster oder Zusammenhänge zu erkennen und nutzbar zu machen – meist mithilfe spezieller Algorithmen.
Big Data bezeichnet vor allem die Verarbeitung großer Datenmengen und die Technologien, die das ermöglichen. Data Mining hingegen ist ein Analysewerkzeug, das auf solche umfangreichen Daten angewendet wird, um darin Muster und verwertbare Informationen zu entdecken. Es hilft dabei, Wissen aus Daten zu gewinnen, das ohne automatisierte Verfahren in der Masse kaum erkennbar wäre.
Data Mining kommt beispielsweise bei Prognosen zum Customer Lifetime Value, der Optimierung von Cross- und Upselling, Kundensegmentierung, Kampagnenoptimierung oder Preisoptimierung zum Einsatz.
Zu den wichtigsten Methoden zählen Klassifikation, Cluster-Analyse und Assoziationsregeln. Sie ordnen Daten Klassen zu, gruppieren ähnliche Objekte oder erkennen Zusammenhänge und Muster in Abläufen.
CRISP-DM (Cross Industry Standard Process for Data Mining) ist ein branchenübergreifendes Modell mit sechs Phasen, das Data-Mining-Prozesse standardisiert und anpassbar strukturiert.
Du möchtest erfahren, wie du das volle Potenzial deiner Daten ausschöpfen kannst?
Sieh dir unsere Webinar-Aufzeichnung zum Thema an!
