
E-book – The Digital Salesperson – Reinforcement Learning in E-commerce
Get comprehensive insights into the use of reinforcement learning for personalizing online shops.
Artificial intelligence (AI) has become indispensable in many companies. It helps to automate processes, offer customers new services, and further develop products. In e-commerce, for example, AI is used for personalization, in the form of chatbots, and in ecommerce search engine engines. One form of artificial intelligence is supervised learning. Read our article to find out what this model entails, how it works, and what advantages and challenges it presents.

Here'swhatyou can expect to find in this blog article:
What is supervised learning?
How does supervised learning work?
When is supervised learning used?
Advantages of the AI model
Challenges related to supervised learning
Other forms of machine learning
Conclusion: Supervised learning offers great potential for online shops
Frequently asked questions about supervised learning
Supervised learning referstoan approach to shaping artificial intelligence (AI). As with any form of machine learning, AI must be trained using algorithms and statistical models in order to draw relevant conclusions from a specific data set. In addition to supervised learning, machine learning is divided into semi-supervised learning, unsupervised learning, and reinforcement learning. All of these forms serve to develop or improve new products, processes, and services.
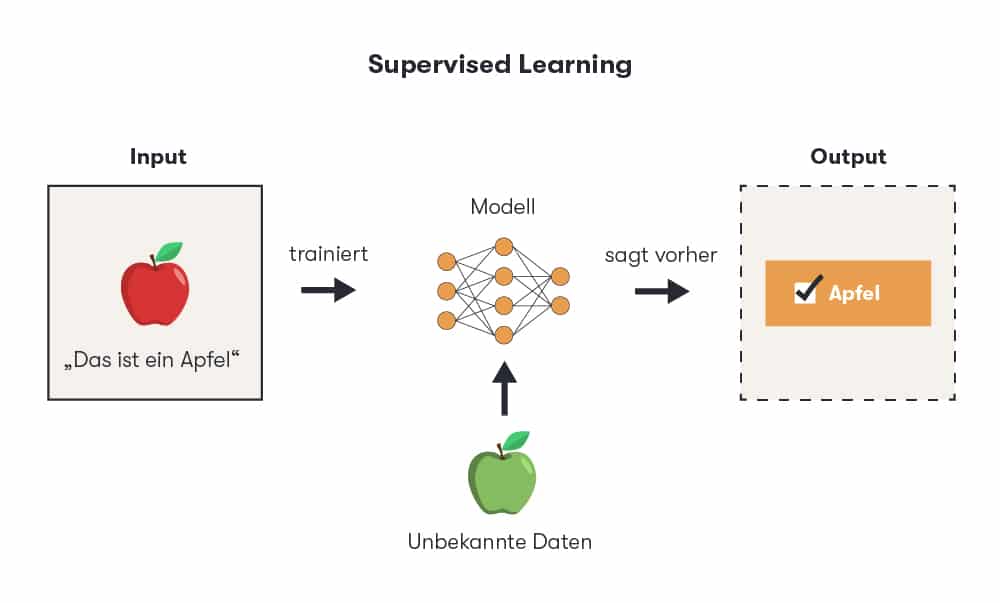
In supervised learning, data scientists train a computer algorithm and monitor it during the learning process. They first provide it with a large amount of input data, each piece of which carries a label for the required output. The result is therefore known in advance. The algorithm is trained until it can reliably recognize the underlying patterns and relationships between input and output.
Stay up to date on personalization: Sign up for the Epoq newsletter.Sign up now!
The machine then undergoes a test phase with input data without any obvious labels. Here, it makes its own decision as to which output is correct and compares its result with the one specified by the developers. The differences or specific predictions are used for optimization in the next learning phase. The accuracy of the algorithm measured in this way shows how well it has already learned and what can be expected in practical use. The goal: The algorithm should deliver the most accurate output possible when it is fed with unknown data without labels after the test phase.
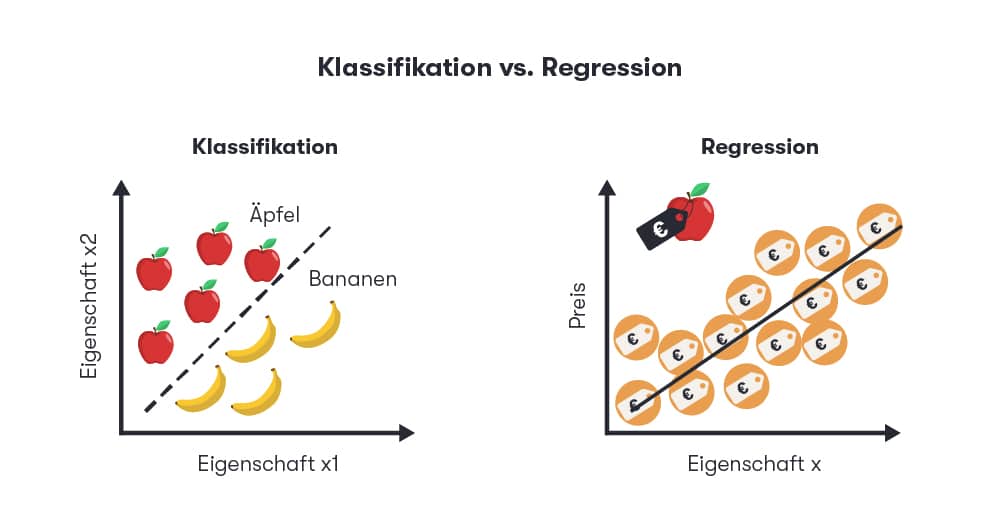
This form of artificial intelligence is already being used for numerous applications in e-commerce. It is particularly suitable for classifications and regression analyses:
Supervised learning helps solve real-world problems, such as detecting credit card fraud or filtering spam, by automating various processes. This saves time and money in the long run.
Based on previous experience, the machine can predict future developments. In the case of spam, for example, it recognizes certain words that appear in the email text, subject line, or sender address. Training the AI helps to obtain an accurate idea of the object classes to be evaluated. In the long term, this can automate and standardize the time-consuming evaluation and classification of large data sets. A well-trained AI outperforms a human operator, not only freeing up human resources but also reducing the likelihood of errors.
In order for the machine to reliably recognize correlations, the data must be well prepared. This is because incorrect data or insufficient preparation of the data poses a major challenge. Unsupervised learning "compensates" for this by having a human interpret the results, adjust the parameters, and recalculate them. However, since this is primarily done manually, it is very time-consuming and costly. Problems in the data or a lack of preparation are not only a challenge for supervised learning, but also for all other learning methods. Deep learning can compensate for this problem in part by using an extremely large amount of computing time and data, but well-prepared data also helps with this method, of course. This is where the "garbage in, garbage out" principle applies, because the output depends largely on the data that is put in.
If there are duplicates, missing content, or missing links in the data set, the AI does not know what to do with it. The same applies if the test data differs from the training data set. The machine must not be trained too precisely on the training data. Otherwise, the effect of so-called overfitting occurs: only if a data input matches the specified variables exactly can it be classified in the corresponding category. Supervised learning is not the only method confronted with this challenge. Deep learning is also not immune to this effect.
Furthermore, diverse data is important so that the machine can evaluate as many different scenarios as possible. For example, if it is supposed to learn to distinguish between humans and animals in images, it should see not only dogs as animals, but also giraffes, elephants, and gorillas. Data scientists therefore need sufficient knowledge about the different object classes in order to clearly distinguish them for the AI.
Reinforcement learning is also affected by the problems mentioned above, and in some cases even more so due to the nature of the learning process.
In addition to supervised learning, there are three other forms of machine learning: unsupervised learning, semi-supervised learning, and reinforcement learning.
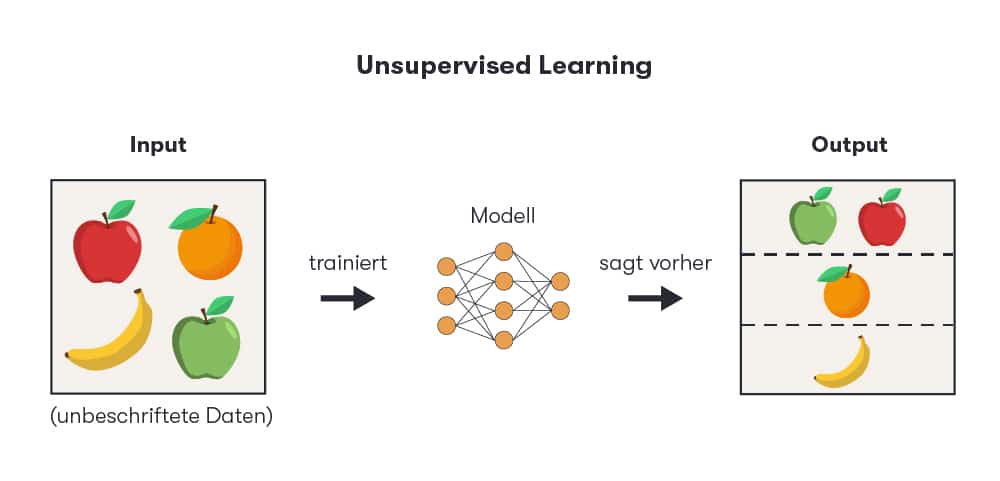
In unsupervised learning , the machine receives data that has not been previously labeled. The AI must figure out for itself what patterns and similarities exist between the data. To do this, it needs a sufficiently large amount of data—much more than in supervised learning—in order to reliably cluster it and draw logical conclusions.
One example of the use of this form of artificial intelligence is the creation of segments for target group analysis. This can in turn be used to deliver personalized content to different segments.
Semi-supervised learning is a hybrid form of the two. During training, the machine receives data sets with labels as well as those without. This form of machine learning is suitable in cases where there is insufficient high-quality data with labels available. A typical example of its application is facial recognition. It is sufficient to tag a specific person in a few images for the AI to independently find other images in which that person is depicted.
Stay up to date on personalization: Sign up for the Epoq newsletter.Sign up now!
In the reinforcement learning model, data scientists use rewards and punishments to teach artificial intelligence a specific behavior. The algorithm independently learns a strategy through trial and error with the goal of maximizing rewards. Originally used for learning board games, reinforcement learning now optimizes numerous processes in e-commerce. If you would like to learn more about reinforcement learning, please read our blog article series on the reinforcement learning process.
You can use artificial intelligence in a variety of ways in your online store to get your customers excited about your brand and generate higher sales. It is necessary to select the appropriate AI model for each specific application. Supervised learning has great potential to optimize the processes and products in your online store. Use AI to filter your customer service emails, offer your customers personalized content, or obtain forecasts of future sales.
Supervised learning is a form of machine learning. Data scientists train a machine to recognize connections between data and draw conclusions from them. The result is known in advance, so that the AI can learn to improve by comparing the calculation result with the specified value. Example: filtering spam from incoming emails.
In supervised learning, a computer algorithm is first trained with prepared data sets. Each input carries a label for the required output (result). The AI model then undergoes a test phase with additional data until the output corresponds as closely as possible to the required results.
This form of artificial intelligence is particularly suitable for classifications and regression analyses, i.e., the search for easily comprehensible correlations between variables. It helps to solve real-world tasks such as categorizing blog articles or detecting credit card fraud.
Training artificial intelligence involves a great deal of manual effort and time. The data must be well prepared, diverse, and clearly defined in its context.
In supervised learning, the algorithm is fed labeled data so that the artificial intelligence can recognize patterns in the data sets. In unsupervised learning, the data is not labeled. This means that the AI must establish connections between the individual variables itself. Semi-supervised learning combines both forms: some of the data is labeled, while the rest is not.
Want to learn more about reinforcement learning in e-commerce?
Then get our e-book on the topic!

You are currently viewing placeholder content from HubSpot Embedded Content. To access the actual content, click the button below. Please note that doing so will result in data being shared with third-party providers.
More InformationYou are currently viewing placeholder content from HubSpot. To access the actual content, click the button below. Please note that doing so will result in data being shared with third-party providers.
More InformationYou are currently viewing placeholder content from HubSpot Meetings. To access the actual content, click the button below. Please note that doing so will result in data being shared with third-party providers.
More Information