
5.04% increase in sales per session thanks to new personalization strategy at Outletcity Metzingen
Outletcity Metzingen puts its personalization strategy to the test and increases revenue per session by 5.04%.
In the second part of our series on our reinforcement learning process, we discuss how we use real-time analytics to process the browsing history of an online store user in such a way that the agent can work with it and make good decisions. Here, the agent faces the challenge of filtering out relevant information from the mass of collected data in a short period of time so that it can be used for recommendations.

Here's what you can expect to find in this blog article:
Real-time analytics in a nutshell
Real-time analytics for use in online shops
Data collection and enrichment
Influence of previous requests
Influence of the time factor
Comparison with other customers
Information on behavior on pages without recommendations
Recognizing patterns in big data
From big data to smart data for enabling real-time analytics
Compile smart data in real time
Our conclusion on real-time analytics for increased purchase probability
With real-time analytics, data arriving in a computer system is analyzed and processed immediately. This is usually done to help people make decisions within a few minutes or seconds. It can even be used to make automated decisions within a few seconds or milliseconds (e.g., deciding what content to display to a user who is currently visiting the website). For a real-time system, it is particularly important that the analysis results are generated quickly enough so that the associated decisions can also be implemented quickly.
Stay up to date on personalization: Sign up for the Epoq newsletter. Register now!
Our agent should make automated decisions in real time to provide relevant recommendations in an online shop. When an online shopper visits a page that includes a recommendation widget, a request is sent to our server. The server interprets the request and creates a numerical vector(Fig. 1) with information about the request for the agent. Based on the numerical vector, the agent decides on one or more actions (e.g., set the price range of the e-commerce recommendations to $40 to $60). These decisions influence the rule chain used to determine the actual products to be recommended. These products are then returned to the user's browser. There, the products are displayed in the widget. This entire process takes only a few milliseconds.
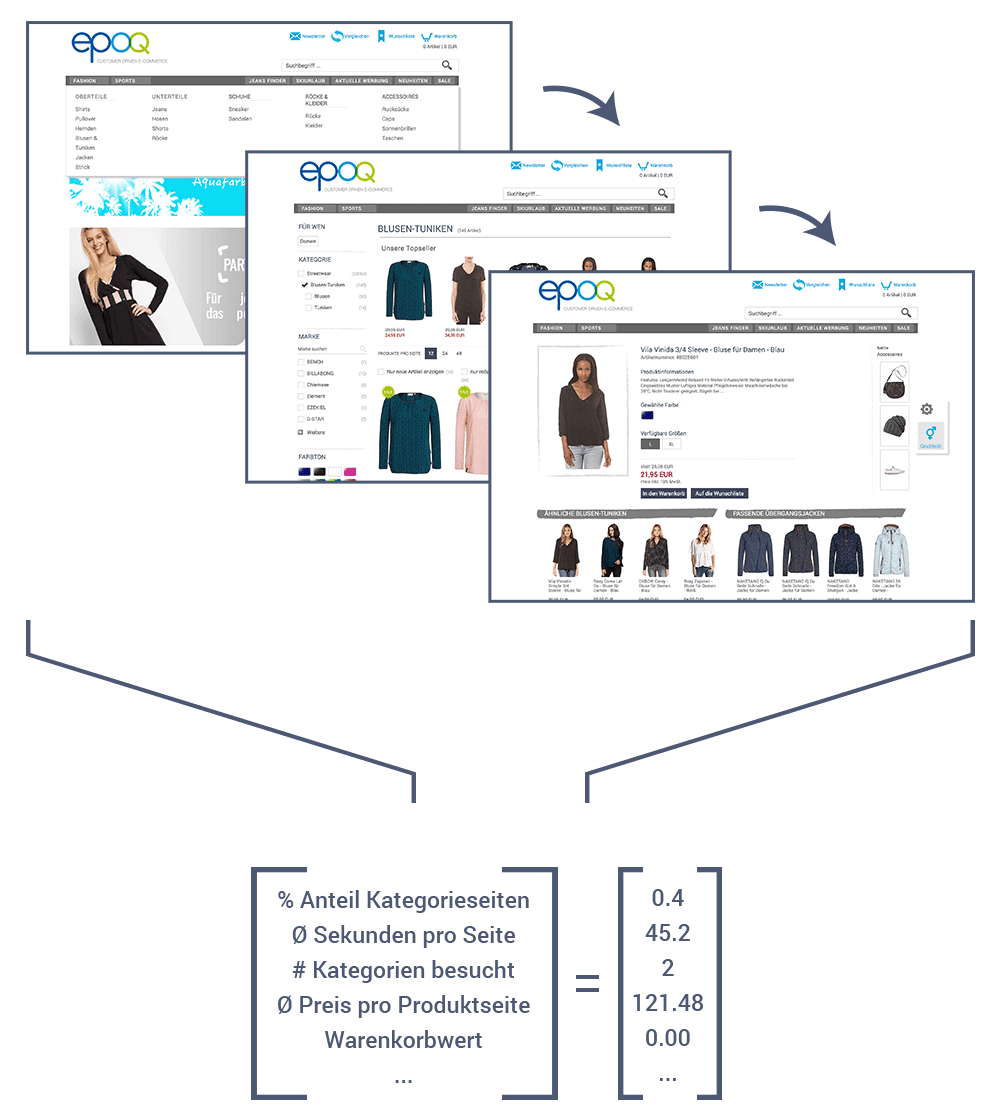
Fig. 1: Number vector with information about the call
This naturally raises the question of how the server interprets the request and creates the number vector for the agent. The challenge here is to obtain as much meaningful information as possible and at the same time calculate it within the limited time available.
When the browser requests the recommendation widget, it sends parameters for the call to our server. These parameters include the online shopper's session ID and information about the page being requested, e.g., the ID of a product on a product detail page. The server keeps additional data in its working memory through our knowledge base, which it can use to enrich the call data. It obtains this data from the product catalog and can thus add additional data to the requested product. These can be simple entries such as
be.
The server also has the previous requests for the session and the associated product IDs in its working memory. This allows it to add statistics on all products viewed, e.g.:
In addition, it can be taken into account whether the user always looks at high-priced products or only products from a small number of brands, or whether the proportion of discounted items increases when viewed later.
The last example shows that not only data on the average behavior of the user is collected, but also changes in behavior. This is important because many users continue to browse the website after they have found the product they are looking for. However, they then behave differently (how? E.g., from purposeful to browsing). For each request, the server stores not only the product ID but also the exact time at which the request arrived on the server. From this, it derives a number of things, such as:
The server also compares these observations with other customers. This has yielded the following insights:
That is why the server also links the time and day of the week to the data created so far.
When a user's website visit is transmitted to the server, even if there is no recommendation widget on the website, such as on category overview pages or information pages about shipping costs, the server also links this data. It observes whether the user frequently returns to the previous page and calculates the proportion of time the user spent on category pages or product detail pages.
The server also has excellent capabilities for further enriching the data if cookies are tracked properly and returning users are recognized. This allows the data obtained to be correlated with the respective history. At this point, we could mention many other possible data observations, but the list would then become significantly too long.
The number of data points that the server can collect in this way is enormous. This can quickly add up to several thousand individual data points for a single recommendation query. There are several reasons why it is not a good idea for the agent to process all the data. Above all, the server needs more time to do this. However, our goal is to deliver recommendations in real time.
If there is too much data, it can also be difficult for the agent to recognize important patterns in the data. To understand why this is the case, let's return to the example from the first part of the blog series , in which we teach our dog Benno to fetch a ball.
You could try training in an open space in a pedestrian zone. However, it will be very difficult to teach the dog to run after the thrown ball here. The dog will be bombarded with lots of stimuli. The many visitors it has to avoid, the smell of currywurst stands, the cheering and shouting of children, and last but not least, the lovely female dogs, which are much more interesting than a strange ball flying away. The dog will not be able to concentrate on the essentials.
Something similar happens with our reinforcement learning agent. If you give it too much data to learn from, it can become difficult to distinguish the important patterns from the less important ones.
If you take your dog from the pedestrian zone to the park, there may still be many stimuli that make training difficult. Hunting dogs in particular may develop a desire to chase not only balls, but anything that moves away from them quickly, such as squirrels, cyclists, or bumblebees. They will then chase these as well.
Such effects can also occur when training the agent. For example, customers might be looking at high-priced products in the pet food category and be recommended soccer balls in the $30–$50 price range. At this point, a lot of revenue could be generated. However, this could also be a coincidence and not represent a pattern that the agent should learn. In this case, the agent would incorrectly learn to recommend mid-range soccer balls to our animal-loving customers. The more data the agent is given for training, the higher the risk that such random patterns will occur.
The negative effects of too many stimuli or too much data in training can be counteracted by skillfully reducing the stimuli and data.
A dog makes more progress when training takes place in a room that is as free of distractions as possible. There are no squirrels running around the room, the TV and radio are turned off, and no interesting-smelling food is being prepared in the kitchen. Here, the dog can concentrate much better on the ball and the trainer's gestures.
We also make learning easier for our reinforcement agent by filtering out only the helpful data. At the same time, we ensure that recommendations can be processed in real time. Using simple statistical methods, we determine how well individual data points predict purchases in the store. We also determine which data points, when combined, provide the most diverse information.
If we have, for example, the following four data points for a user
then we see that the first three are statistically correlated. If we want to reduce the number of data points to three by filtering out one date, we would choose one of the first three data points because the last one brings more diversity to the data. We would select the one of the first three that is statistically the least meaningful for predicting purchases. We perform this analysis on thousands of data points until only about 60 to 100 remain.
For example, information about whether the user has been on the main page longer or shorter than other users cannot always be used for a prediction.
Stay up to date on personalization: Sign up for the Epoq newsletter. Register now!
Filtering itself also takes time. When a request is sent to the server, it would take too long to first calculate all the data and then determine which data should be filtered out again. Instead, the data to be retained should be calculated once a day. When a request reaches the server, it checks which data is actually needed and calculates only that data. This allows it to complete the input for the agent in just a few milliseconds.
In order to be able to deliver relevant recommendations in real time, data science expertise is in demand! On the one hand, as much data as possible must be collected, enriched, and then interpreted. On the other hand, the mass of information must be reduced to what is truly meaningful so that it can be displayed in real time. We believe that this process is worthwhile in order to fill shopping carts with relevant recommendations and make online shoppers happy.
The first part of our blog series "Reinforcement Learning Process": How to use reinforcement learning profitably for your online shop (Part 1)
And here's the third part: How to increase your sales with self-learning algorithms (Part 3)
5.04% increase in sales per session: Outletcity Metzingen put its personalization strategy to the test.
Request the case study now!

You are currently viewing placeholder content from HubSpot Embedded Content. To access the actual content, click the button below. Please note that doing so will result in data being shared with third-party providers.
More InformationYou are currently viewing placeholder content from HubSpot. To access the actual content, click the button below. Please note that doing so will result in data being shared with third-party providers.
More InformationYou are currently viewing placeholder content from HubSpot Meetings. To access the actual content, click the button below. Please note that doing so will result in data being shared with third-party providers.
More Information